Papers That Shaped AI Engineering and Agent Development
The academic world produces tens of thousands of AI papers annually. This list is not merely a “high-citation academic ranking”—rather, it’s curated through a dual lens of “real-world engineering impact” and “paradigm shifts in system architecture.”
Readers will notice a tension that reflects reality: some works celebrated by the public as “breakthroughs” (like Stanford’s AI town or free-form multi-agent conversations) are viewed by production engineers chasing 99.9% SLA, monitoring token costs and latency, as wildly uncontrollable “sandbox toys.” Real industrial agents are shedding their early “anthropomorphic” facade and embracing rigorous directed acyclic graphs (DAGs) and state machine control. Understanding this gap—from “academic romance” to “engineering reality”—is essential for AI engineers to level up.
Introduction
As Large Language Models (LLMs) evolved from GPT-1 to today’s Agent era, a misconception has taken hold: that AI application performance is capped by the base model’s capabilities, leaving engineers with little more than “invoking” and “waiting.” Yet from the perspective of frontline AI Engineering and ML Engineering, the model is simply one non-deterministic computation engine (or “brain component”) within the system.
In real enterprise deployments, engineers don’t just ask “what can the model do?”—they ask “at what cost?” From building robust automated evaluation suites (Evals), to navigating the trade-offs between “generation quality” and “response latency”; from abstracting tool calling specifications, to collecting interaction trajectories to build data flywheels—the engineer’s ability to decompose scenarios, control state machines, and construct evaluation systems determines the final product experience. In AI engineering circles, there’s a saying: “Evals are all you need.” Evaluations define the system’s upper bound.
This article surveys the core papers that have profoundly shaped large language models and intelligent agents through the lens of capability stacks, showing how AI engineers evolved from “model alchemists” into “system architects” who master complex state machines and “data flow choreographers.”
Level 0: Foundation & Alignment
Address models’ inability to understand human language or their lack of common knowledge.
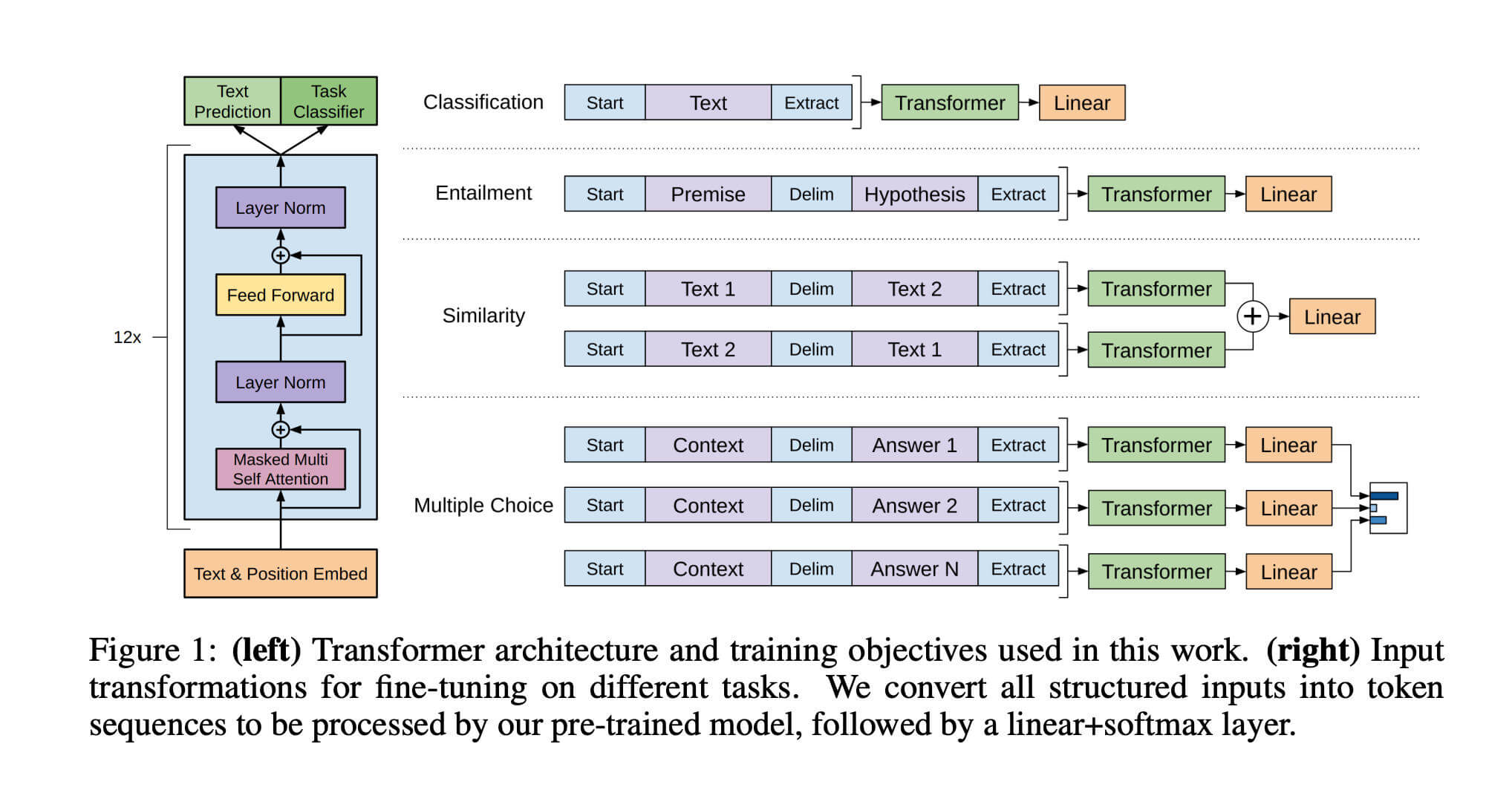
1. GPT-1: Establishing the Paradigm (2018)
Paper: Improving Language Understanding by Generative Pre-Training (2018)
Before GPT-1, natural language processing (NLP) faced the “one task, one model” dilemma: translation required one architecture, text classification another. GPT-1 proposed a revolutionary idea: what if we first trained a “general language understanding model” on massive unlabeled text, then simply fine-tuned it for specific tasks? This established the “pre-training + fine-tuning” paradigm.
Its architecture comprised 12 layers of Transformer Decoder (~117 million parameters). In the first unsupervised pre-training phase, the model learned to predict the next word on vast book corpora, mastering syntax and world knowledge; in the second supervised fine-tuning phase, it adjusted parameters on task-specific labeled data.
This breakthrough ended the era of designing separate architectures for each task, establishing the industrial standard that dominated NLP for years, while proving Transformer’s superiority over previous RNN/LSTM architectures for long-text dependencies.
Although PyTorch has become the dominant deep learning framework, GPT-1’s code was still trained using TensorFlow, and the codebase has been open-sourced on GitHub.
2. GPT-2: Toward Generalization and Zero-Shot (2019)
Paper: Language Models are Unsupervised Multitask Learners (2019)
GPT-2’s core idea explored “zero-shot learning.” The OpenAI team discovered that when models grew sufficiently large and trained on enough data, they no longer needed task-specific fine-tuning. They proposed an ambitious concept: “all NLP tasks are fundamentally next-token prediction.”
Architecturally, GPT-2 maintained a similar structure but expanded parameters 10x (to 1.5 billion) using the high-quality, highly diverse WebText dataset. In usage, it eliminated fine-tuning entirely, instead feeding prompts to test direct output—for example, given "English: Hello, French: ", it would predict "Bonjour".
GPT-2 demonstrated “scale is all you need”: simply increasing model parameters and data significantly boosted performance. It showed models could solve problems without task-specific data, relying on massive general knowledge. Its text generation was so convincing that it sparked widespread debate about AI safety and fake news.
GPT-2 remains open source on GitHub, and like GPT-1, uses TensorFlow rather than PyTorch for training and inference.
3. GPT-3: Scaling Laws and Emergence (2020)
Paper: Language Models are Few-Shot Learners (2020)
Model Card: openai/gpt-3
GPT-3 completely revolutionized the fine-tuning paradigm with “in-context learning / few-shot learning.” It abandoned updating model parameters entirely, instead using “prompt engineering” to let models learn tasks from context. Just a few examples (few-shot) in the prompt enabled instant pattern recognition and application.
Its scale expanded to a staggering 175 billion parameters, with training data devouring much of the internet (Common Crawl). At inference, the model performs no gradient descent, relying entirely on powerful pattern matching to understand input and generate continuations.
GPT-3’s most shocking feature was “emergence”: when parameters broke the hundred-billion threshold, the model suddenly gained complex logical reasoning and code generation capabilities absent in smaller models. It spawned prompt engineering as a new interaction paradigm, and through commercial APIs, proved general LLMs could serve as infrastructure supporting countless downstream applications, officially launching the generative AI commercial wave.
OpenAI adopted a closed-source approach starting with GPT-3 and officially began commercialization.

4. GPT-3.5 (InstructGPT): Alignment with Human Intent via RLHF (2022)
Paper: Training language models to follow instructions with human feedback (2022)
Despite GPT-3’s power, it remained essentially a “text completer.” It might complete your question with another question, or generate irrelevant rambling, because it didn’t truly understand “user intent.” GPT-3.5 (InstructGPT) centered on “alignment”—shifting optimization from simple “next-token probability maximization” to “human intent and values alignment.”
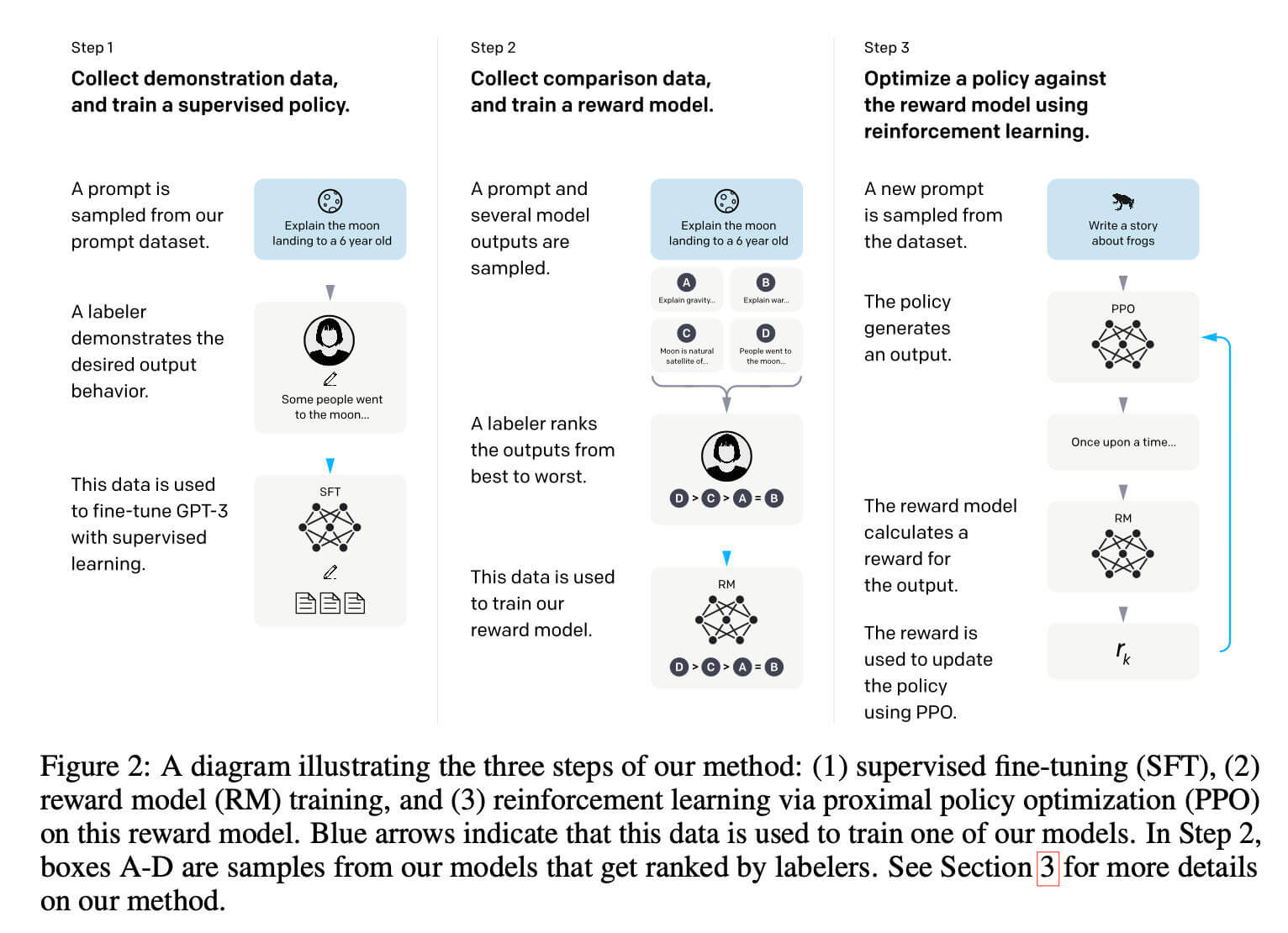
To achieve this, GPT-3.5 employed the famous RLHF (Reinforcement Learning from Human Feedback) three-stage training. Stage 1: Supervised Fine-Tuning (SFT) using expert-written high-quality responses to teach dialogue format and logic. Stage 2: Reward Model (RM) training, where humans rank multiple responses, training a scoring model for “what’s better.”
Stage 3: Proximal Policy Optimization (PPO), a reinforcement learning process where the main model generates responses, the reward model scores them, high scores are reinforced, and low scores are penalized. Through large-scale automated training, the model achieves substantial self-evolution, aligning responses with human preferences and eventually becoming ChatGPT’s foundation.
Level 1: Prompt Engineering and Inference-Time Compute
Address unreliable single-pass output and lack of deep reasoning. This highlights the engineering trend of Scaling Laws shifting from training to inference.
1. Chain-of-Thought (CoT) (2022)
Paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022)
When handling complex math or logic problems, traditional prompting gives the model a problem and expects a direct final answer. Chain-of-Thought (CoT) proposed an incredibly simple yet effective prompting method: in few-shot examples, demonstrate not just “question” and “answer,” but also the “intermediate reasoning steps” from question to solution.
This approach significantly boosted large language model performance on complex tasks like arithmetic, commonsense, and symbolic reasoning. Crucially, the paper found this reasoning ability “emerges” only in models exceeding hundred-billion parameters—CoT can even backfire on smaller models.
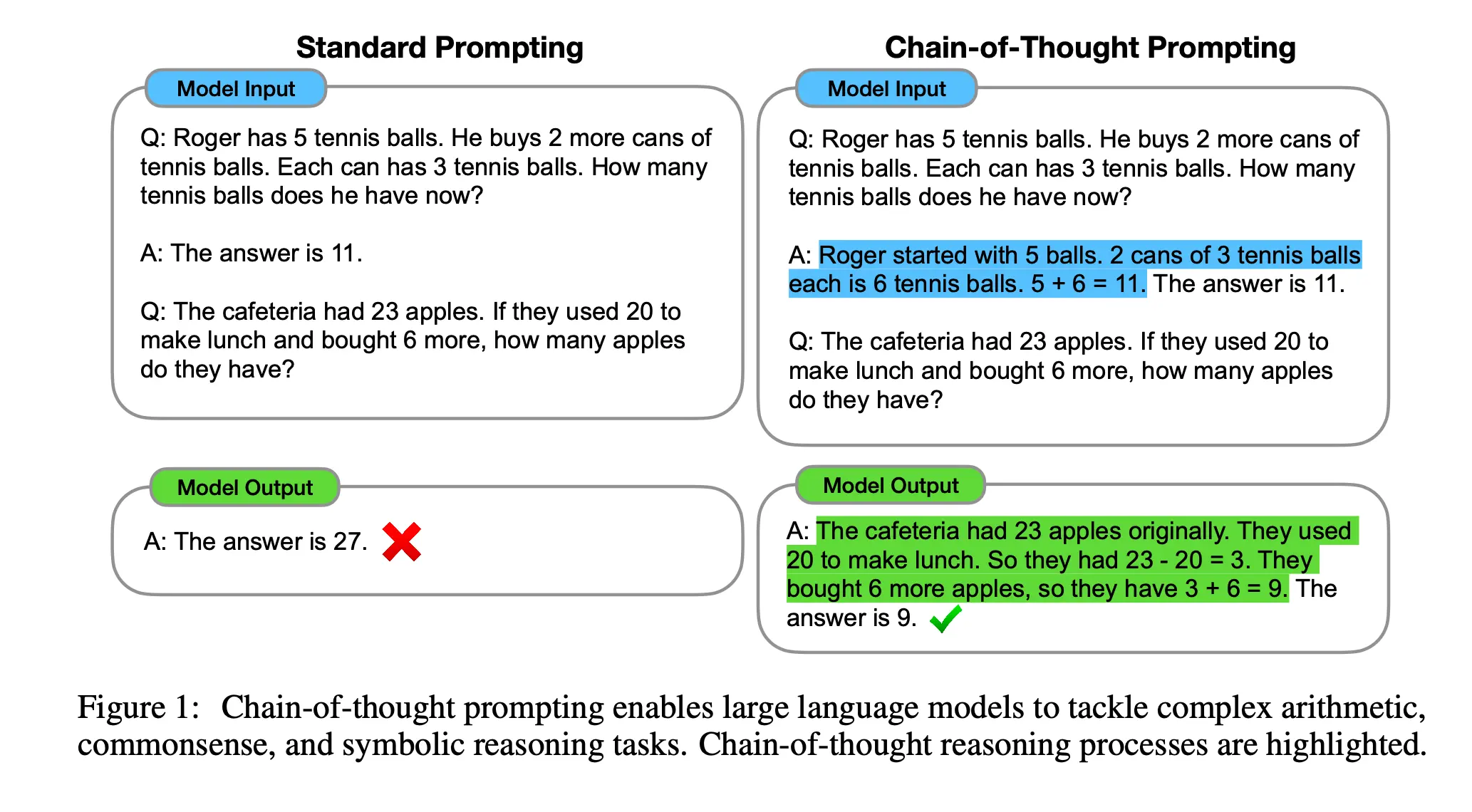
CoT not only dramatically improved accuracy but also provided interpretability and debuggibility. By outputting reasoning steps, researchers can “see” the model’s thought process, pinpointing specific errors when they occur. This technique, unlocking potential without additional training using just a few examples, fundamentally changed industry understanding of model capabilities.
2. Zero-Shot CoT: Relic of Its Era (2022)
Paper: Large Language Models are Zero-Shot Reasoners (2022)
This paper caused massive sensation by discovering an incredibly simple yet powerful “incantation”: just add Let's think step by step to the prompt, directly awakening zero-shot logical reasoning. This forces models into “analytical” mode (System 2 thinking), boosting GPT-3’s accuracy on GSM8K math from 17.7% to 78.7%.

But from today’s AI engineering perspective, this is a “relic of its era”—a trick that seemed magical only because underlying model capabilities were so weak. Today, models like GPT-4o, Claude 3.5, or native RL reasoning models (DeepSeek R1, OpenAI o1) have internalized this behavior through alignment. In modern system engineering, we prefer structured XML or JSON (e.g., enforcing <thinking> tags) for robust verification of model reasoning states, rather than relying on fragile natural language phrases. The historical significance lies in proving to the industry that reasoning potential was always latent in models, requiring only the right trigger.
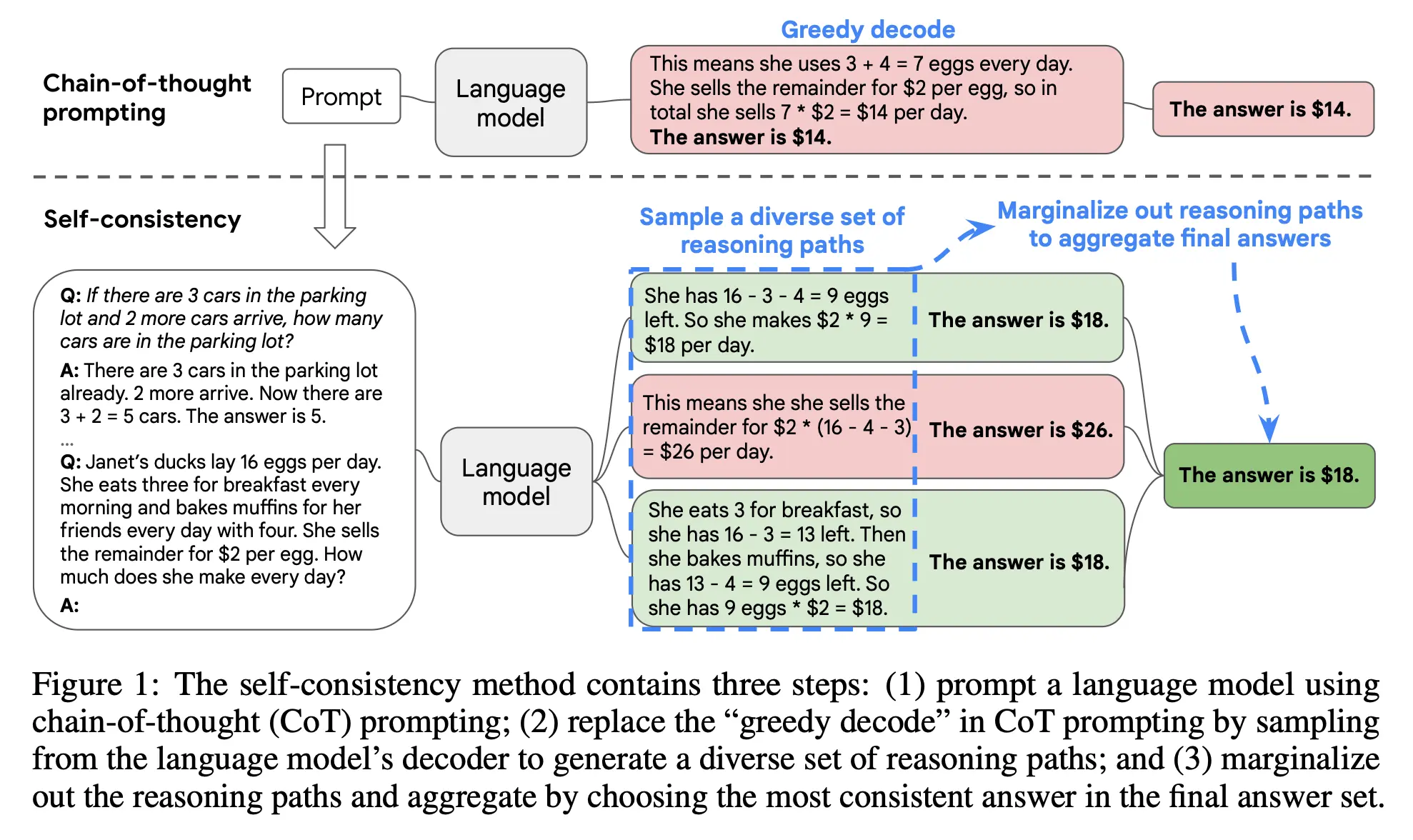
3. Self-Consistency (2022)
Paper: Self-Consistency Improves Chain of Thought Reasoning in Language Models (2022)
Self-consistency addresses the problem of occasional reasoning failures in LLMs. The intuition is straightforward: complex reasoning problems have multiple correct solution paths that converge on the same answer; conversely, when models err, their error paths diverge randomly.
Thus, rather than single-pass generation (greedy decoding), generate multiple diverse reasoning paths (e.g., 10 responses), aggregate results, and select the most frequent answer as final output (majority voting). Across multiple arithmetic and commonsense reasoning benchmarks, self-consistency significantly improved chain-of-thought prompting performance.
This paper established the important paradigm of “trading inference-time compute for intelligence.” It proved that without retraining, simply increasing inference computation can dramatically improve reliability. But in production, this capability comes at steep token cost and linear latency increase. Balancing generation quality against response time became the core challenge for engineers deploying such solutions.
4. Tree of Thoughts (ToT): The Cost Nightmare and Offline Distillation (2023)
Paper: Tree of Thoughts: Deliberate Problem Solving with Large Language Models (2023)
While chain-of-thought is effective, it’s “greedy”—generating linearly step-by-step, unable to backtrack if intermediate steps err. Tree of Thoughts (ToT) injects human “System 2” thinking into LLM generation, modeling problem-solving as search on a “thought tree.” At each node, the model generates multiple possible “next steps” (branching), then acts as “evaluator” scoring them to decide whether to continue exploring, prune, or backtrack.
But to ML engineers, ToT is a production nightmare that devours costs. While delivering exceptional reasoning capabilities, its exponentially growing nodes cause catastrophic token consumption—a single request can take minutes and easily trigger API rate limits. Consequently, ToT is rarely adopted in real-world high-concurrency online services; engineers prefer breaking tasks into deterministic single-step flows or using high-concurrency Best-of-N sampling. Today, ToT’s primary value has shifted to compute-rich offline scenarios as a tool for synthesizing high-quality trajectory data to distill small language models (SLMs).
5. Process Supervision (PRM) (2023)
Paper: Let’s Verify Step by Step (2023)
When training AI to solve complex math problems, traditional practice is “outcome supervision”: only checking final answer correctness after the model outputs the entire process. This leads to “right answer, wrong reasoning”—models getting correct answers through flawed logic. This paper proposed “process supervision (PRM)” evaluating each reasoning step, proving far superior to outcome supervision.
To prove this, OpenAI released PRM800K, a dataset of 800,000 human-labeled steps, using active learning to have models generate confusing problems for humans to correct. During inference, models generate multiple solutions, then use trained process reward models (PRM) to score each step, selecting the highest-scoring path. This achieved ~78% accuracy on complex math benchmarks.
This research introduced the concept of “negative alignment tax”: usually, making AI safer and more interpretable sacrifices capability, but process supervision proved that step-by-step correct thinking improves both interpretability and problem-solving. This theory laid the foundation for OpenAI o1 model’s powerful long-chain reasoning and led the new industry paradigm of training specialized verifiers.

Level 2: Tool Calling and Environmental Perception
Address models’ lack of hands and eyes, information barriers, and hallucinations.
1. Toolformer: Elegant Concept, Superseded Path (2023)
Paper: Toolformer: Language Models Can Teach Themselves to Use Tools (2023)
LLMs have always struggled with math calculations or retrieving current facts. Toolformer explored how to enable language models to autonomously decide when and how to call external tools. Unlike traditional methods relying on massive human annotation, Toolformer proposed innovative self-supervised learning: during training, the model attempts to insert API calls; if results help predict the next token more accurately, it’s kept as positive samples. Ultimately, models learned to naturally insert instruction markers like <API_Call>.
However, this academically elegant paper was quickly superseded in practice by “In-Context Learning + robust JSON parsing.” Toolformer depends on fine-tuning to teach specific models API calling syntax. This proves inflexible in production: if business API parameters change tomorrow, must we re-fine-tune the model? Despite this, Toolformer first established the paradigm of “models autonomously deciding when to call external tools,” directly inspiring the entire plugin ecosystem.
2. Gorilla and Function Calling: Structured Output Engineering Standards (2023)
Paper: Gorilla: Large Language Model Connected with Massive APIs (2023)
After academia proved models could call tools, engineering hit a wall: how to make unreliable generative models stably output syntactically correct JSON parameters? If parsing fails, the entire agent state machine crashes. The Gorilla paper proved through retriever-aware training that fine-tuning could dramatically reduce LLM API hallucination and dynamically adapt to documentation changes.
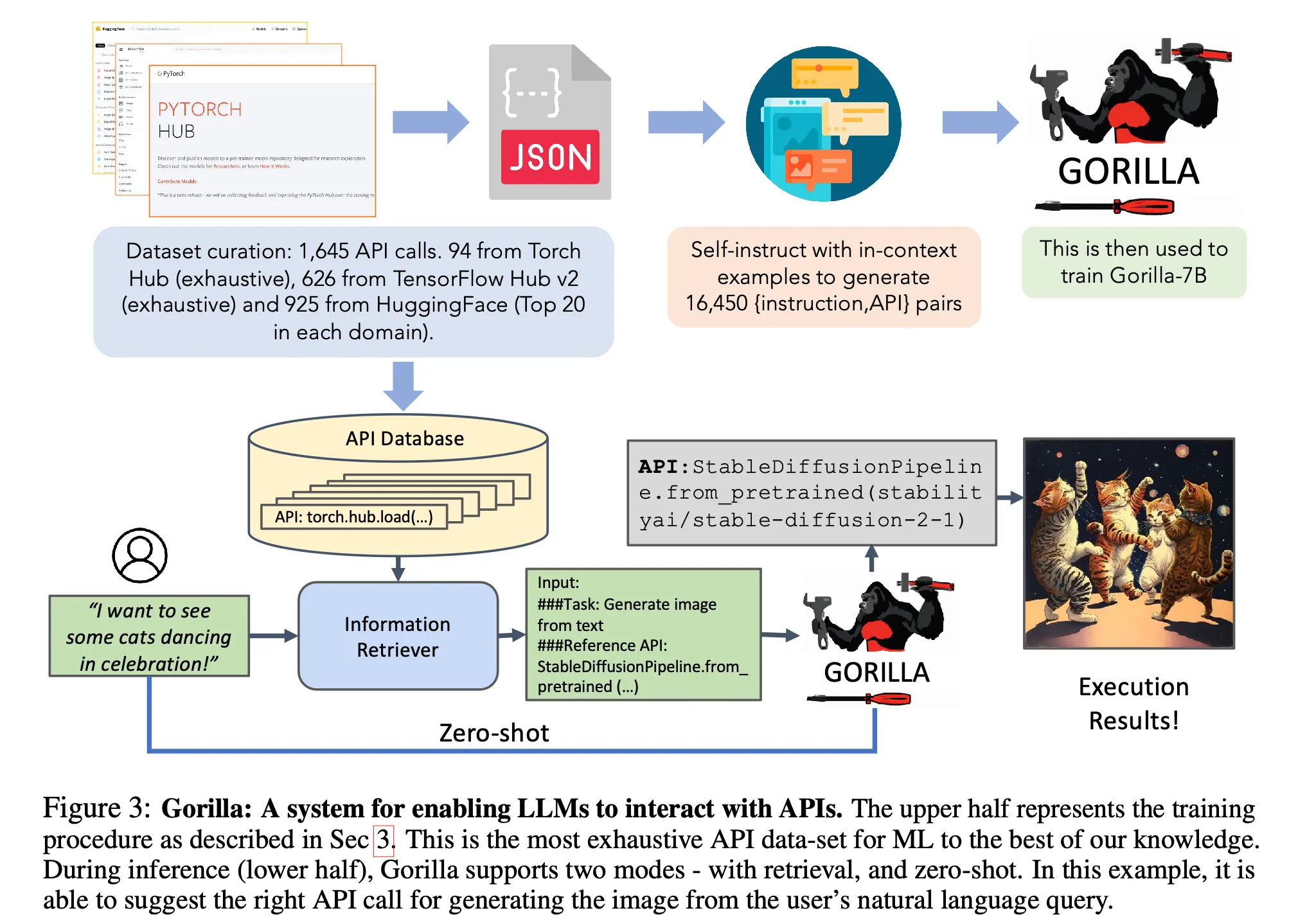
Subsequently, OpenAI officially launched Function Calling. To AI engineers, this feature is the core turning point for agents truly moving to large-scale industrial deployment. It abandoned unreliable regex extraction, shifting prompt parsing “grunt work” into the model’s underlying logic, enabling stable deterministic interaction with external databases and business APIs, laying the unshakeable foundation of modern agent toolchains.
3. FLARE: Active Retrieval for Long-Context Hallucination (2023)
Paper: Active Retrieval Augmented Generation (2023)
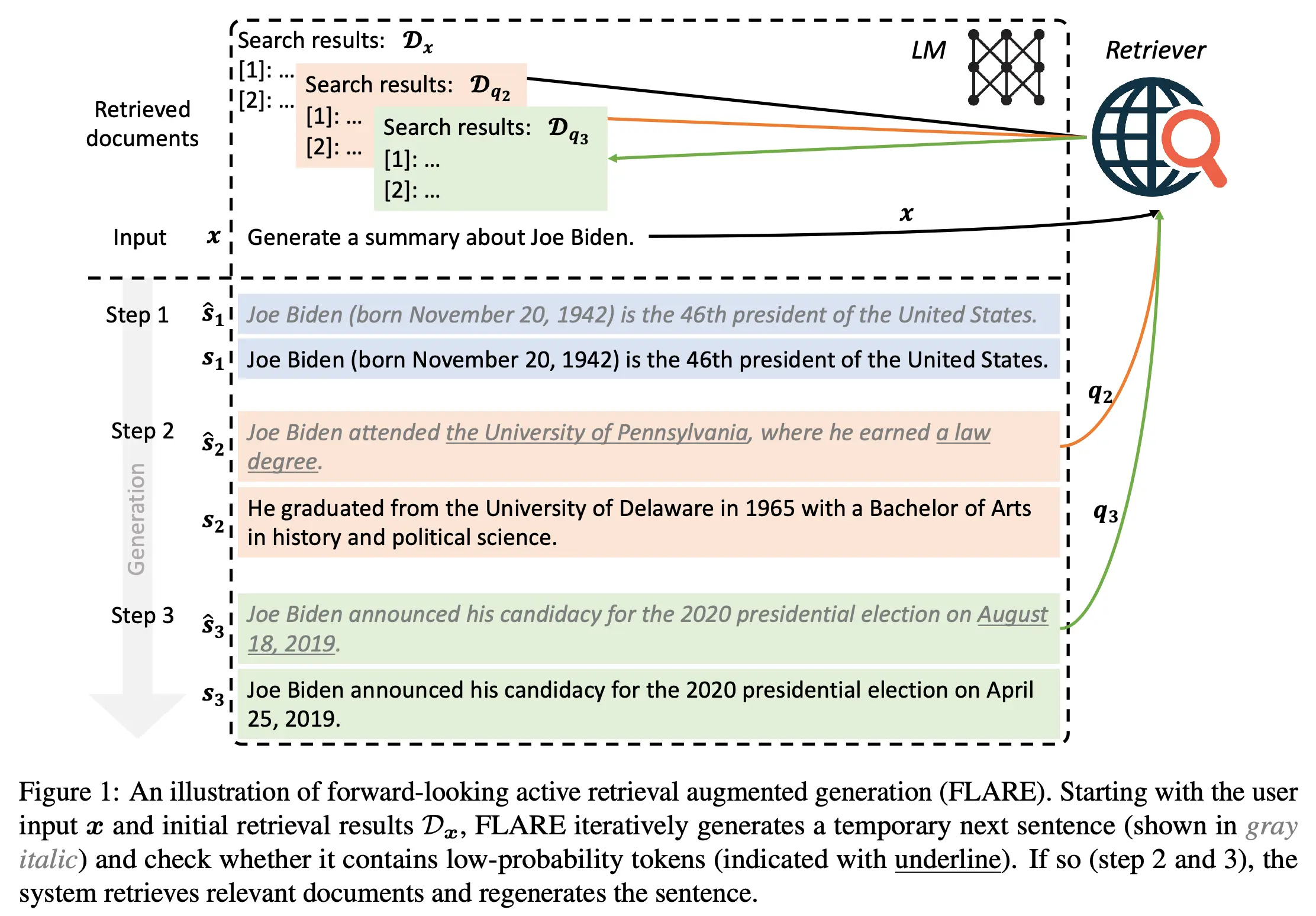
Retrieval-Augmented Generation (RAG) is the most effective engineering means to solve LLM hallucinations and enterprise private data access. Traditional RAG typically performs only one “static retrieval” before generation. But when generating long technical documents, models often “forget” context mid-way and start hallucinating.
FLARE proposed a “forward-looking active retrieval” mechanism: during generation, models monitor their confidence (probability) in real-time. Once detecting extremely low confidence for upcoming tokens, they proactively pause, generate a “predictive sentence” as a query to search external knowledge bases, then continue generation based on retrieval results. This fine-grained state machine control dramatically improves reliability and factual correctness for long-chain generation tasks.
4. AppAgent: GUI Agents Beyond API Limits (2023)
Paper: AppAgent: Multimodal Agents as Smartphone Users (2023)
For a long time, AI agents operating external software relied heavily on system backend APIs. The fatal weakness: once software lacks open APIs, agents are helpless. AppAgent proposed a highly disruptive multimodal agent framework: having LLMs directly operate real smartphones like humans, by “seeing” screen screenshots and tapping, swiping with touch gestures.
AppAgent introduced innovative “two-stage learning.” In exploration stage, agents build cognition of app interfaces through autonomous attempts or observing human demonstrations; in deployment stage, they identify screen elements based on knowledge bases and directly operate apps to complete complex tasks. It kicked off the “Computer Use” agent era, laying important groundwork for later OS-level agent development.
Level 3: Cognitive Architecture and Memory Systems
Address models’ tendency to forget and inability to self-improve.
1. ReAct: The “Double Helix” State Machine of Thought and Action (2022)
Paper: ReAct: Synergizing Reasoning and Acting in Language Models (2022)
Before ReAct, LLMs were primarily used for pure reasoning (prone to hallucination from lack of external information) or pure action (directly calling tools without planning, prone to infinite loops). The ReAct framework ingeniously interwove “reasoning” and “acting,” enabling models to “think while doing.”
ReAct’s workflow follows a specific loop: Thought -> Action -> Observation. From an engineering perspective, ReAct effectively encapsulates LLMs as controlled non-deterministic state machines. By introducing observation nodes, developers can capture external environment errors (error handling) and force models to fix these errors in the next loop. This solid engineering abstraction defines the underlying runtime logic of modern frameworks like LangChain.
ReAct is the foundation of almost all agent control frameworks. Its innovation lies in defining the basic steps of the agent event loop—a pattern that was subsequently adopted by LangChain (create_react_agent()), CrewAI, AutoGen, and others.

2. Reflexion: Closed-Loop Reflection and Memory Feedback (2023)
Paper: Reflexion: Language Agents with Verbal Reinforcement Learning (2023)
Traditional agents cannot learn from failures and repeat the same mistakes. The Reflexion framework gives AI human-like “post-mortem reflection” capabilities, creating a new method for self-improvement and evolution without fine-tuning model weights, termed “verbal reinforcement learning.”
When agents fail tasks, the system launches a “reflector” module. It analyzes failure trajectories and environmental feedback (e.g., compilation errors), generates reflection notes in natural language stored in long-term memory, and feeds them as additional context prompts in the next attempt. Reflexion transforms agents from one-time consumables into “problem solvers” that continuously evolve through trial and error.

3. Generative Agents: Sandbox Toys of Cognitive Architecture (2023)
Paper: Generative Agents: Interactive Simulacra of Human Behavior (2023)
This paper, commonly called “Stanford AI Town,” placed 25 LLM-driven characters in a 2D sandbox world. Its breakthrough was designing a cognitive architecture with “memory stream”: the system records all experiences, periodically polls to “reflect” and extract high-level cognition, then “plans,” and “retrieves” vast memory banks during action.
Strip away the “Westworld” romanticism, and advanced AI engineers view this architecture with skepticism: in production B2B/B2C systems, this hyper-anthropomorphic design is an uncontrollable “sandbox toy.” Production systems cannot afford code agents or customer service bots with “freewheeling reflection mechanisms” that consume massive amounts of tokens. Real-world production memory systems eschew expensive LLM-based reflection in favor of precise vector databases combined with traditional SQL for rule-based filtering. Despite limited production deployment, it provides valuable insights for game NPCs and social science simulations.
Level 4: Multi-Agent Collaboration and Workflow Orchestration
Address robustness of complex multi-step tasks, moving from purely agentic approaches to disciplined workflow orchestration.
1. CAMEL: The End of Multi-Agent Crosstalk (2023)
Paper: CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society (2023)
CAMEL proposed a “role-playing framework,” setting strict roles for two agents (user agent sends instructions, assistant agent executes), attempting to standardize effective agent communication and solve control chaos.
In academia, CAMEL inspired multi-agent development; but in engineering, having two LLMs advance tasks through “free conversation (even with defined roles)” proved disastrous. Probabilistic generative models in free conversation readily fall into infinite loops, mutual flattery, or topic drift. Modern industrial multi-agent systems have abandoned this uncontrollable “chat flow” in favor of directed acyclic graphs (DAGs, like LangGraph) or strict state machines. Previous agent output must be valid JSON, strongly validated by code logic before passing downstream. CAMEL’s history demonstrates both the promise of “multi-agent collaboration” and the severe limitations of “uncontrollable conversation” in production systems.
2. MetaGPT: Multi-Agent Pipeline Introducing Human SOPs (2023)
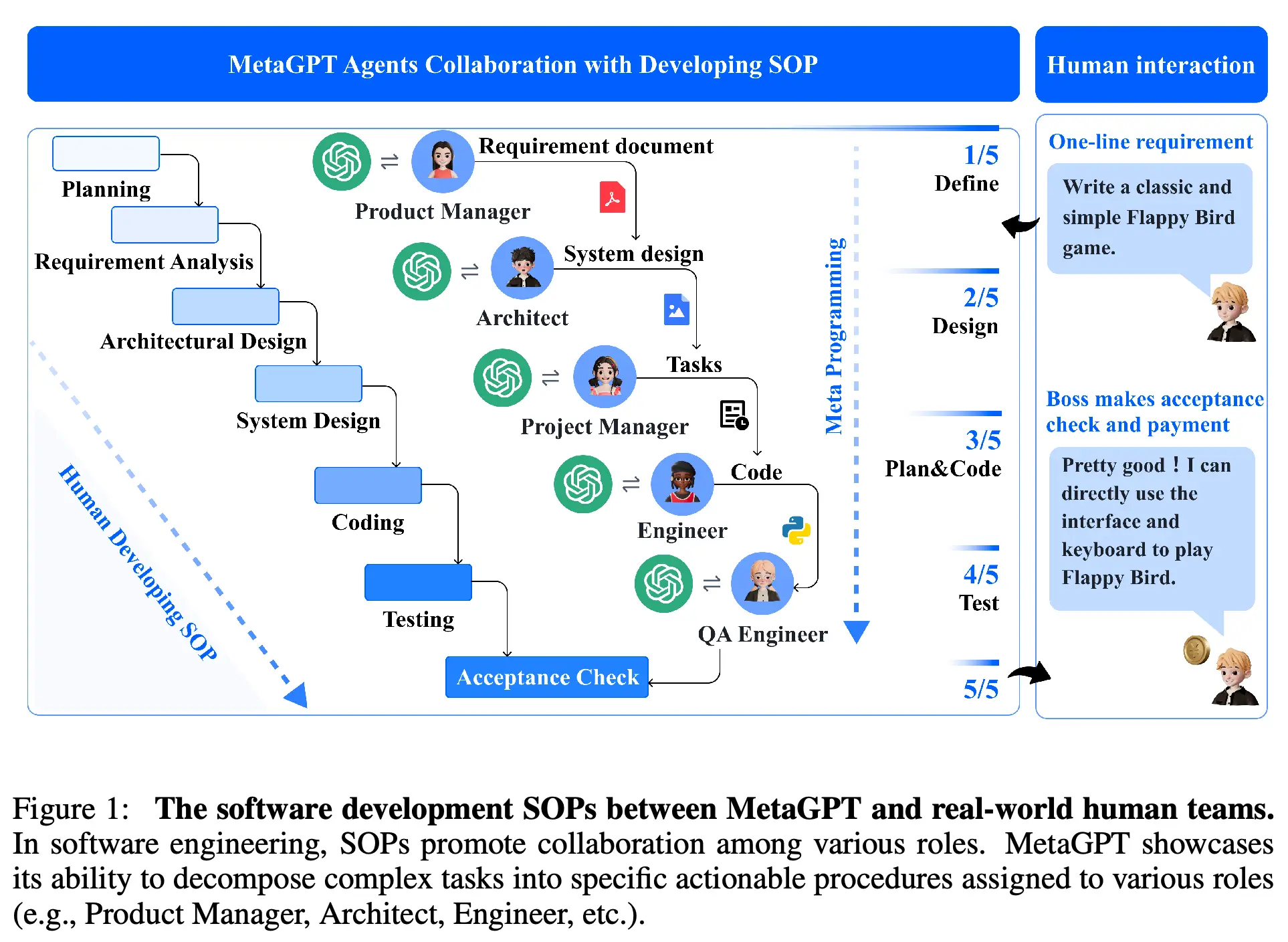
Paper: MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework (2023)
Addressing the pain point of free conversation drifting, MetaGPT creatively introduced Standard Operating Procedures (SOPs) from human enterprise management into multi-agent collaboration.
Within MetaGPT’s framework, core roles like product manager, architect, engineer, and QA are predefined. Agents no longer hand off work through casual chat, but strictly follow assembly-line patterns—upstream roles output structured documents (PRDs, UML diagrams), while downstream roles develop and test based on these documents. This approach of encoding software engineering practices into prompts introduces strong “self-correction” and “logic verification” through enforced intermediate documentation outputs.
3. AutoGen: Multi-Agent Orchestration and Conversational Programming (2023)
Paper: AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation (2023)
Microsoft’s AutoGen provides a framework letting developers define various agents with different capabilities and tool permissions, setting interaction topologies between them to develop complex LLM applications.
For AI engineers, AutoGen’s greatest value lies in elegant concurrency control, context state sharing, and truncation strategies. Complex tasks are decomposed to different agent state machines, dramatically alleviating single model context window overflow pressure, making complex task engineering orchestration reality.
4. Mixture-of-Agents (MoA): Model Collective Intelligence (2024)
Paper: Mixture-of-Agents Enhances Large Language Model Capabilities (2024)
As monolithic LLM development approaches computing limits, MoA architecture discovered a “collaboration phenomenon”: when models are provided other models’ outputs as reference, they often generate higher-quality responses than thinking alone. In “proposer” layers, multiple different LLMs generate initial responses in parallel; in “aggregator” layers, models synthesize and refine, letting pure open-source model combinations surpass closed-source giant GPT-4o in benchmarks.
However, engineers must face reality: MoA dominates offline benchmarks, but in high-concurrency online services, its multi-level, multi-model network request overhead is an engineering nightmare. It finds more use as infrastructure for generating high-quality distillation data than as a direct consumer-facing interface.
Level 5: Vertical Domain Practice and Full-Stack Automation
Move toward open environments and autonomous operation in codebases.
1. SWE-bench: The Ultimate Benchmark of Real Software Engineering (2023)
Paper/Dataset: SWE-bench: Can Language Models Resolve Real-World GitHub Issues? (2023)
SWE-bench changed AI programming capability testing rules. It requires AI, in real open-source libraries containing hundreds of thousands of lines of code (like Django, pandas), to locate and fix bugs based on issue descriptions.
This challenging task requires models to handle ultra-long context, understand complex environment dependencies, and perform multi-step reasoning. SWE-bench’s emergence directly triggered the explosion of AI software engineering agents (like SWE-agent, OpenHands, Devin). It signals to industry: in complex vertical domains, Evals (automated evaluation suites) quality determines the upper bound of agent capability. Developers must make systems learn like human programmers: add logs, run code, check errors, then iterate.
2. Voyager: Embodied Intelligence and Skill Accumulation (2023)
Paper: Voyager: An Open-Ended Embodied Agent with Large Language Models (2023)
Voyager uses LLMs as core controllers, building an embodied agent in Minecraft capable of continuous exploration, learning new skills, and autonomous operation.
Its core mechanism comprises three key modules: an “automatic curriculum” maximizing exploration, a “skill library” storing executable code, and iterative prompting based on environmental feedback. When code successfully executes completing tasks, it’s encapsulated as “skills” permanently saved. Voyager first demonstrated “lifelong learning” without human intervention.
3. The AI Scientist: Toward Fully Automated Research Loop (2024)
Paper: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery (2024)
The AI Scientist marks AI agents officially entering “full-stack scientific research” deep waters. It proposed the world’s first comprehensively automated AI system for scientific research processes, autonomously completing the loop from proposing innovative ideas, conducting experiments, to writing complete academic papers.
The system even built-in an “automated reviewer” capable of scoring generated papers and suggesting revisions like top conference reviewers. It broke the traditional perception that “AI can only serve as auxiliary tool,” demonstrating AI’s enormous potential as “independent researcher.”
Level 6: Infrastructure, Self-Evolution and Miniaturization
Address fragmentation, high inference costs, and edge deployment challenges.
1. Agent Infrastructure Standardization: MCP (2024)
Project/Protocol: Model Context Protocol (MCP) (2024)
MCP proposed a standardized client-server architecture, standardizing how agents share, retain, and retrieve context across different models and tools.
MCP’s core breakthrough completely decouples “data sources” from “LLMs.” Once developers write standard MCP Servers for data sources, any MCP-supporting client can directly read data. This makes cross-application multi-step agent workflows stable and reliable, laying network protocol foundations for open agent ecosystems.
2. Reinforcement Learning and Reasoning Revolution: DeepSeek R1 (2025)
Paper: DeepSeek R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2025)
DeepSeek R1 first proved that purely through large-scale reinforcement learning (RL), with minimal or no labeled data, models can spontaneously emerge advanced self-reflection, error correction, and long chain-of-thought capabilities.
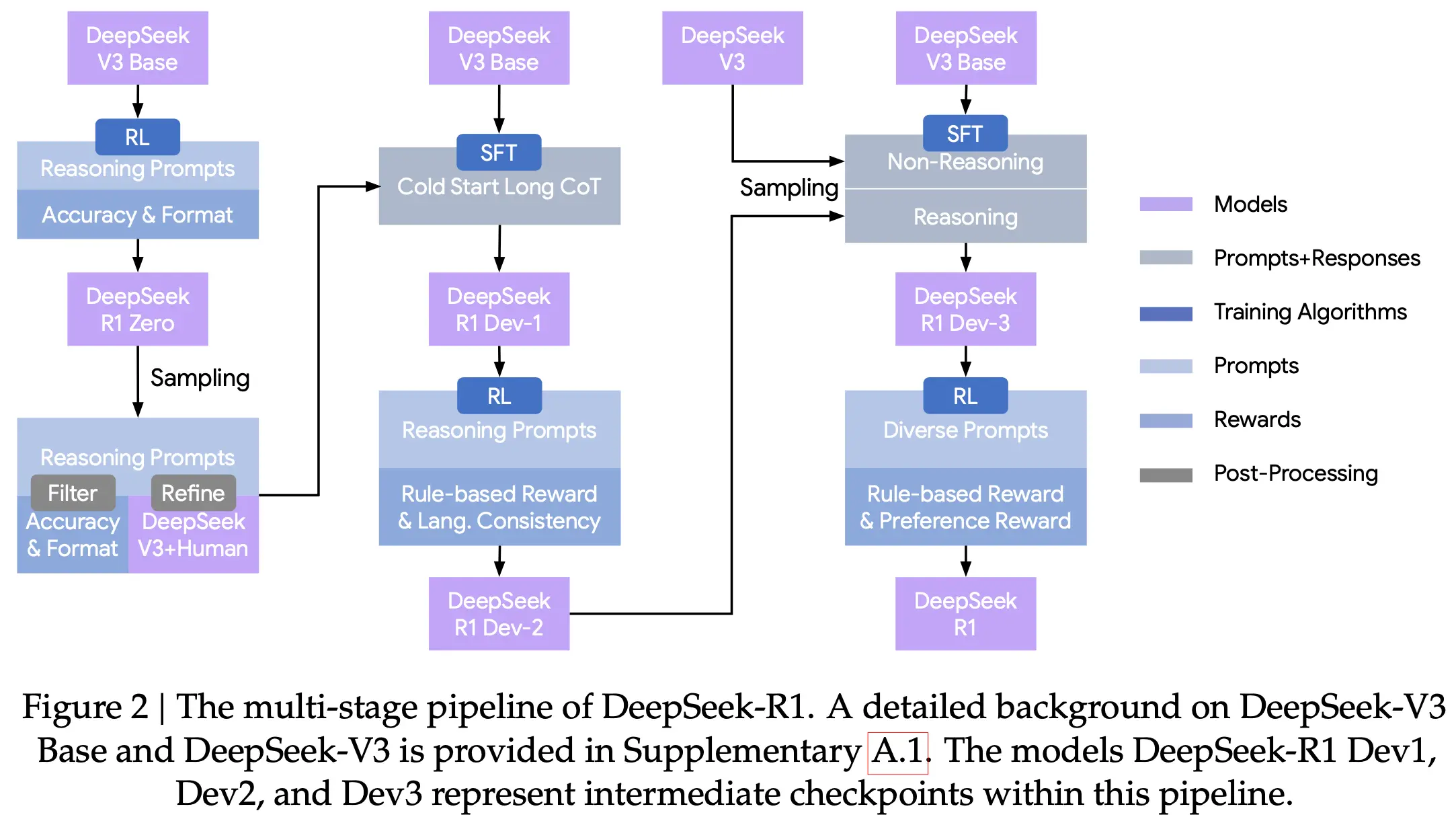
Its core mechanism designed an incredibly clever reward function, removing reward models needing human preferences from traditional RLHF, directly giving hard rewards based on math problem correctness or code compilation success (rule-based reward). This thoroughly revolutionized agent reasoning foundations, reducing top-tier logical reasoning capability cost by orders of magnitude.
3. Miniaturization and Collaboration: SLM Trends in Agentic AI (2025)
Paper: Small Language Models (SLMs) are the Future of Agentic AI (2025)
As agents see wide application, people discovered using billion-parameter massive models for simple tasks wastes computing resources. Small Language Models (SLMs) are considered future agent system cornerstones.
Researchers demonstrated “manager-worker” architecture: extremely strong LLMs serve as managers responsible for global planning; specific execution work goes to fine-tuned SLM workers. This enables AI agents to deploy on edge devices with extremely low latency and cost.
Conclusion
Reviewing this magnificent evolution from GPT-1 to Multi-Agent, to today’s automated workflows, the answer to “where is the AI engineer’s space?” has already emerged in every paradigm shift.
Initially, we thought the space was in “training”—finding convergence in vast parameter spaces; later, we thought the space was in “prompting”—attempting to use spell-like prompts to awaken sleeping giants; but now, the true engineering space lies in “system building” and “data flywheels.”
LLMs themselves are becoming computers’ new CPUs. They have amazing computing power and general knowledge, but as non-deterministic components, still hallucinate, forget, and generate high latency. AI engineers’ mission is no longer polishing this CPU’s transistors, but building around it: rigorous state machine motherboards (workflow orchestration and error recovery), high-speed cache and hard drives (RAG and memory systems), peripheral network cards (Function Calling and MCP), and most critically—evaluation monitors (Evals).
Furthermore, skilled AI and ML engineers recognize that every agent trial and rollback produces invaluable trajectory data. By collecting these interactions for SFT or RLHF feedback, specialized small models (SLMs) grow increasingly powerful. In this era, we’re not just silicon brain system architects, but data flow choreographers. Models determine single-response floors, while superior engineering architecture and continuously running data flywheels determine AI products’ absolute ceilings. This is our frontier.