Agent Harness:AI工程师必须掌握的设计方法论
引言:模型不是瓶颈
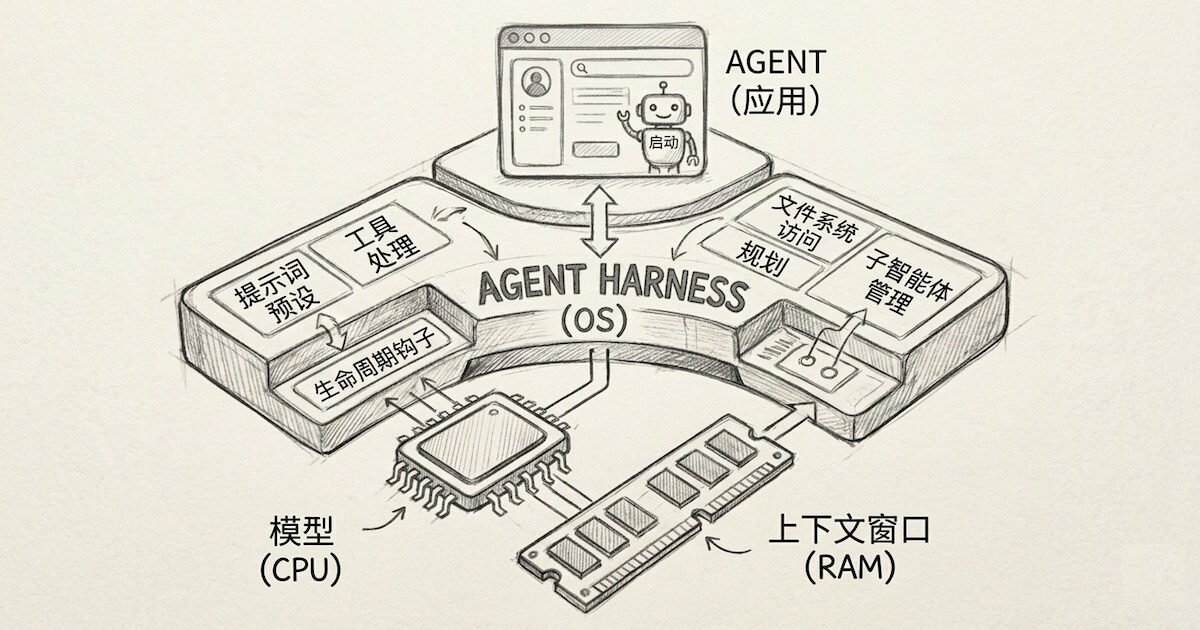
基础模型让程序第一次有了“大脑”,但要让Agent真正可靠地工作,你还需要给它装上“手脚”和“神经系统”——这就是Agent Harness的职责。
The old moat was model quality. The new moat is your agent harness.
这句话说到了点子上。如果2025年是Agent元年,2026年就是Agent Harness之年。为什么?因为模型智能是“spiky”的——在某些任务上表现出色,在某些任务上却会不可预测地失败。Harness的作用,就是平滑这种能力波动,给Agent提供一个可靠的执行环境。
看看一线团队的实践:
- Manus:一年内重写了5次Harness [1]。
- LangChain的Open Deep Research:一年内重构了4次架构 [2]。
- Vercel:砍掉80%的工具后,步骤更少、Token消耗更低、响应更快 [3]。
核心结论:训练一个更好的模型需要6个月,但构建一个有效的Harness需要数千工程小时——这才是真正的竞争壁垒。
1. 什么是Agent Harness
1.1 从Test Harness说起
软件工程师对Test Harness应该很熟悉——它是为测试提供受控执行环境的基础设施,管理测试用例、执行测试、收集结果、生成报告。
Agent Harness是这个概念在AI领域的延伸:
为Agent提供结构化执行环境的基础设施,让Agent可被控制、可观测、可评估。
和Agent框架的区别是什么?
- Agent框架(LangChain、CrewAI这类)提供API和抽象层,本质上是无预设(Unopinionated)的Agent Loop,最典型的如ReAct Agent。调用模型、解析工具调用、执行工具、填充执行结果、一次次重复,所有的框架都能很好完成这类事情。
- Agent Harness则提供Agent完整运行环境的前者没有涉及的其他能力:停止条件、最大循环次数、提示词和上下文注入节点、工具调用结果格式、提醒模型约束条件等。
简单说:框架帮你快速搭建Agent,Harness让Agent在生产环境稳定运行。
1.2 核心架构:四层设计
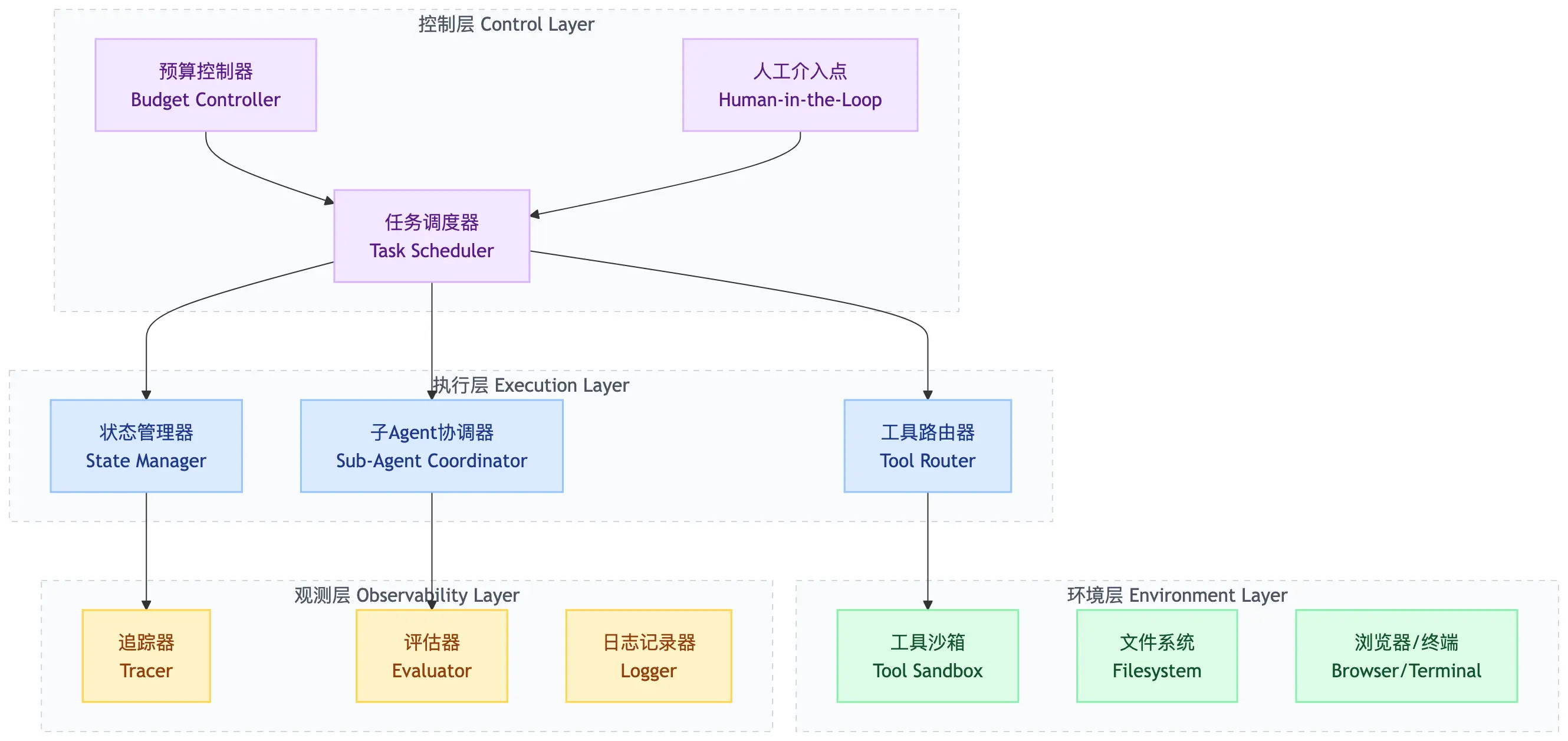
- 控制层定义Agent“能做什么”:任务怎么分解、预算是多少、什么时候需要人介入;
- 执行层决定Agent“怎么做”:工具怎么调用、状态怎么流转、多Agent怎么协作;
- 环境层提供Agent“和什么交互”:沙箱环境、文件系统、外部API;
- 观测层告诉你Agent“做了什么”:追踪链路、评估结果、记录日志。
2. Tool Router:工具路由系统
工具是Agent与外部世界交互的唯一通道,Tool Router是这个通道的“交通管制中心”。
2.1 声明式Schema驱动
from pydantic import BaseModel, Field
from typing import Callable, Any
class ToolSchema(BaseModel):
"""工具的元数据描述"""
name: str = Field(..., description="工具名称")
description: str = Field(..., description="工具功能描述")
parameters: dict[str, Any] = Field(..., description="JSON Schema格式参数")
examples: list[dict[str, Any]] = Field(default_factory=list) # Few-shot示例
category: str = Field("default", description="工具分类,用于层次路由")
class Tool(BaseModel):
schema: ToolSchema
handler: Callable
model_config = {"arbitrary_types_allowed": True}三个设计原则:
- 工具自描述:工具通过Schema声明能力,而不是硬编码逻辑
- Schema驱动:用JSON Schema定义输入输出契约,自动验证
- Few-shot内置:在Schema里写示例,帮助LLM理解工具用法
2.2 四层路由策略
| 层次 | 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| L1 | 名称匹配 | 简单快速 | 容易冲突、无语义 | 工具少于5个 |
| L2 | 关键词匹配 | 有语义理解 | 关键词难设计 | 5-20个工具 |
| L3 | LLM语义路由 | 理解意图 | 延迟和成本高 | 20+个复杂工具 |
| L4 | 混合层次路由 | 平衡性能与准确 | 实现复杂 | 生产环境推荐 |
生产建议:用L4混合策略——先用名称和关键词快速筛选候选集,再用LLM做语义排序。
2.3 工具幻觉:三层防御
Agent有个典型问题:它把工具调用失败理解成“数据不存在”,而不是“我犯错了”。
举个例子:Agent调用不存在的sales_api.get_report(),收到ToolNotFoundError,但它理解成“销售报告不存在”,然后编造了一个假报告。
三层防御机制:
from enum import Enum
from pydantic import BaseModel
from typing import Any
class ToolErrorType(str, Enum):
PARAMETER_ERROR = "parameter_error"
EXECUTION_ERROR = "execution_error"
NOT_FOUND = "not_found"
class ToolResult(BaseModel):
"""强制结构化的工具返回,防止幻觉"""
success: bool
data: Any = None
error: ToolErrorType | None = None
error_message: str | None = None- 第一层:Schema验证
- 工具调用前检查参数类型和必填字段
- 返回明确的
PARAMETER_ERROR,别让工具执行失败
- 第二层:执行反馈
- 工具必须返回结构化的
ToolResult - 区分
NOT_FOUND(工具不存在)和EXECUTION_ERROR(执行失败)
- 工具必须返回结构化的
- 第三层:输出验证
- 强制Agent解析工具返回值
- 禁止在工具返回为空时编造结果
from pydantic import ValidationError
class ToolRouter:
def route(self, tool_name: str, **kwargs) -> ToolResult:
tool = self.get_tool(tool_name)
if not tool:
return ToolResult(
success=False,
error=ToolErrorType.NOT_FOUND,
error_message=f"Tool {tool_name} not found"
)
# 第一层:Schema验证
try:
validated_args = tool.schema.parameters_model(**kwargs)
except ValidationError as e:
return ToolResult(
success=False,
error=ToolErrorType.PARAMETER_ERROR,
error_message=str(e)
)
# 第二层:执行工具
try:
result = tool.handler(**validated_args.model_dump())
return ToolResult(success=True, data=result)
except Exception as e:
return ToolResult(
success=False,
error=ToolErrorType.EXECUTION_ERROR,
error_message=str(e)
)3. State Management:状态管理
状态是Agent执行过程中的“记忆”,良好的状态管理是可靠性的基础。
3.1 四种状态
| 类型 | 定义 | 示例 | 生命周期 |
|---|---|---|---|
| 会话状态 | 消息历史、上下文窗口 | messages: [] | 会话级别 |
| 任务状态 | 当前步骤、已完成步骤 | current_step: "searching" | 任务级别 |
| 领域状态 | 业务实体状态 | calendar_events: [] | 跨会话 |
| 系统状态 | 资源使用、错误计数 | retry_count: 3 | 执行级别 |
关键点:不同类型的状态需要不同的持久化策略。
3.2 Checkpoint:三种持久化策略
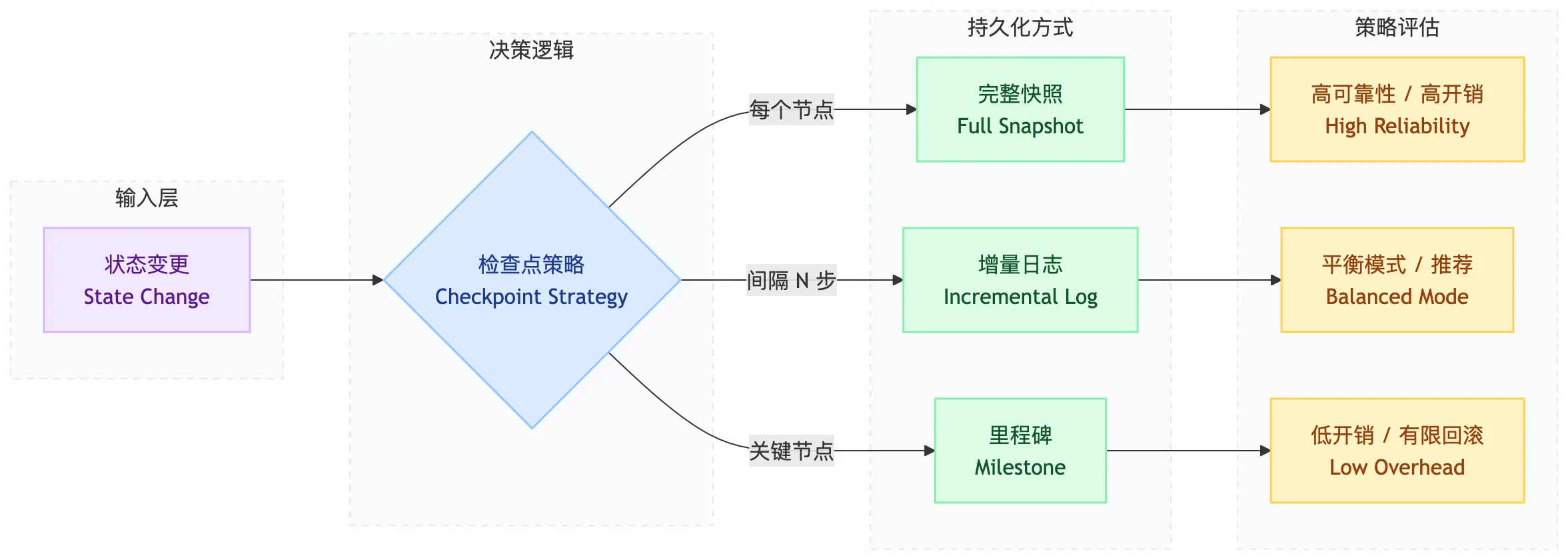
- Full Snapshot:每个节点后保存完整状态
- 适合:短流程(<10步)、状态体积小
- 优点:回滚快速
- 缺点:存储开销大
- Incremental Log:只保存变更,重放时恢复
- 适合:长流程(>10步)、状态体积大
- 优点:存储高效
- 缺点:回滚需要重放
- Milestone:只在关键节点保存
- 适合:资源受限、可接受部分回滚
- 优点:开销最小
- 缺点:回滚精度有限
3.3 时间旅行:状态回溯
from typing import Generic, TypeVar, Any
from pydantic import BaseModel, Field
from datetime import datetime
import copy
T = TypeVar('T')
class Checkpoint(BaseModel):
version: int
timestamp: datetime = Field(default_factory=datetime.now)
state: dict[str, Any]
metadata: dict[str, Any] = Field(default_factory=dict)
class StateManager(Generic[T]):
def __init__(self, initial_state: T):
self.current_state = initial_state
self.checkpoints: list[Checkpoint] = []
self.version = 0
def checkpoint(self, metadata: dict | None = None) -> int:
"""创建检查点"""
self.version += 1
state_data = (self.current_state.model_dump()
if isinstance(self.current_state, BaseModel)
else copy.deepcopy(self.current_state))
checkpoint = Checkpoint(
version=self.version,
timestamp=datetime.now(),
state=state_data,
metadata=metadata or {}
)
self.checkpoints.append(checkpoint)
return self.version
def rollback(self, version: int) -> T:
"""时间旅行:回滚到指定版本"""
for cp in reversed(self.checkpoints):
if cp.version == version:
if hasattr(self.current_state, "__class__") and issubclass(self.current_state.__class__, BaseModel):
self.current_state = self.current_state.__class__.model_validate(cp.state)
else:
self.current_state = copy.deepcopy(cp.state)
return self.current_state
raise ValueError(f"Version {version} not found")时间旅行有什么用?
- 调试:回到失败前的状态,复现问题
- 错误恢复:回到上一个健康状态
- 分支探索:尝试不同的决策路径
权衡:存储空间 vs 回溯精度
4. Evaluation:评估系统
没有评估,你就不知道Agent是否真的“成功”了。
4.1 多维评估
| 维度 | 指标 | 测量方式 | 目标 |
|---|---|---|---|
| 正确性 | TSR、准确性 | 自动化测试、人工标注 | 最大化 |
| 效率 | Token数、步数、延迟 | 计数器、计时器 | 最小化 |
| 稳定性 | 成功率、崩溃率 | 错误追踪 | 最大化 |
| 安全性 | 越界尝试、危险操作 | 规则引擎 | 零容忍 |
4.2 分层评估架构
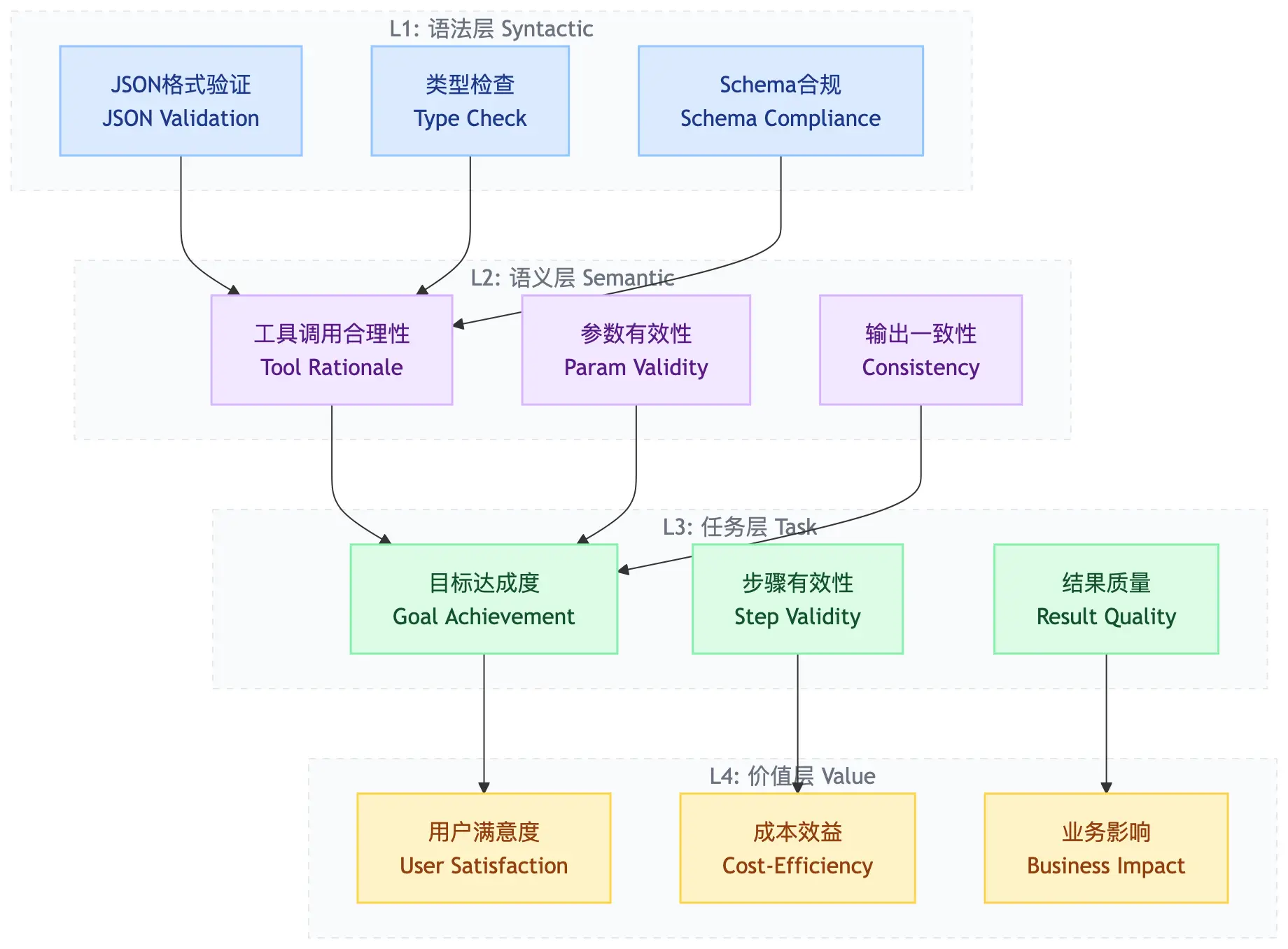
- L1 语法层:格式对不对?JSON格式、类型检查、Schema合规。
- L2 语义层:调用合不合理?工具是否存在、参数是否有效、输出是否一致。
- L3 任务层:目标达成了吗?目标达成度、步骤有效性、结果质量。
- L4 价值层:创造了价值吗?用户满意度、成本效益、业务影响。
4.3 EvalPipeline实现
from abc import ABC, abstractmethod
from pydantic import BaseModel, Field
from typing import Any
class EvalScore(BaseModel):
value: float = Field(..., ge=0, le=1) # 强制分数在0-1之间
reason: str
metadata: dict[str, Any] = Field(default_factory=dict)
class Evaluator(ABC):
@abstractmethod
def evaluate(self, output: Any, context: dict) -> EvalScore:
pass
class EvalPipeline:
"""评估管道:依次执行多层验证"""
def __init__(self):
self.validators: list[Evaluator] = []
def evaluate(self, output: Any, context: dict) -> dict[str, EvalScore]:
"""执行所有评估器"""
results = {}
for i, validator in enumerate(self.validators):
layer_name = validator.__class__.__name__
results[layer_name] = validator.evaluate(output, context)
# 快速失败:语法层失败则不继续
if i == 0 and results[layer_name].value < 0.5:
break
return results
def get_overall_score(self, results: dict[str, EvalScore]) -> float:
"""加权平均计算综合分数"""
weights = {
"SyntaxValidator": 0.4,
"SemanticValidator": 0.3,
"TaskValidator": 0.3
}
total = sum(
results[k].value * weights.get(k, 0.1)
for k in results
)
return max(0, min(1, total))5. 执行流程控制
5.1 编排模式
- 线性链(Linear Chain):步骤顺序执行,最简单
- 条件分支(Conditional Branching):基于决策点选择路径
- 循环迭代(Loop/Iteration):重试直到满足条件
- 并行执行(Parallel Execution):多任务同时进行
- 递归分解(Recursive Decomposition):任务自顶向下分解
5.2 控制流模式:可控性梯度

- 关键洞察:可控性和灵活性是trade-off。生产环境推荐
- 状态机模式——在可控性和灵活性之间取得了最佳平衡。
5.3 轻量级StateMachine实现
from pydantic import BaseModel, ConfigDict
from typing import Callable, Any
class Transition(BaseModel):
model_config = ConfigDict(arbitrary_types_allowed=True)
from_state: str
to_state: str | Callable
condition: Callable | None = None
class StateMachine:
def __init__(self):
self.states: dict[str, Callable] = {}
self.transitions: list[Transition] = []
self.current_state: str | None = None
def add_state(self, name: str, handler: Callable) -> None:
self.states[name] = handler
def add_transition(self, transition: Transition) -> None:
self.transitions.append(transition)
def start(self, initial_state: str, context: dict) -> Any:
self.current_state = initial_state
result = None
max_steps = 100 # 预算控制:防止无限循环
step = 0
while self.current_state and step < max_steps:
step += 1
handler = self.states.get(self.current_state)
if not handler:
raise ValueError(f"State {self.current_state} not found")
result = handler(context)
self.current_state = self._find_next_state(result, context)
return result
def _find_next_state(self, result: Any, context: dict) -> str | None:
for trans in self.transitions:
if trans.from_state != self.current_state:
continue
if trans.condition and not trans.condition(result, context):
continue
if callable(trans.to_state):
return trans.to_state(result, context)
return trans.to_state
return None5.4 预算控制:四种机制
| 预算类型 | 限制内容 | 防止问题 | 实现方式 |
|---|---|---|---|
| Token预算 | 总Token消耗 | 成本失控 | 计数器 + 强制终止 |
| 步数预算 | 执行步数 | 无限循环 | 计数器 + 退出条件 |
| 时间预算 | 执行时长 | 超时挂起 | 超时中断 |
| 资源预算 | API调用次数 | 资源耗尽 | 配额管理 |
实现原则:预算控制应该是硬约束,触达预算立即终止。
6. 反模式与陷阱
6.1 认知偏差陷阱
| 陷阱 | 症状 | 根源 | 防御 |
|---|---|---|---|
| 工具幻觉 | 编造工具结果 | 将失败误解为“不存在” | 强制结构化返回 |
| 计划幻觉 | 生成不可行计划 | 缺乏预演验证 | 计划验证+预演 |
| 成功幻觉 | 过早宣布完成 | 缺乏完成标准 | 明确验证器 |
6.2 系统性陷阱
上下文溢出:对话历史无限增长
- 解决:滑动窗口、摘要压缩
状态污染:错误状态传播
- 解决:状态隔离、Checkpoint回滚
级联失败:多Agent系统中的错误放大
- 解决:每个Agent独立验证、熔断机制
6.3 工程陷阱
过度抽象:过早引入复杂抽象
- 建议:从具体用例开始,逐步抽象
工具爆炸:注册过多工具导致路由困难
- 建议:工具合并、能力分层
评估盲区:只测开发数据,忽略边缘情况
- 建议:对抗测试、红队演练
7. 框架选型
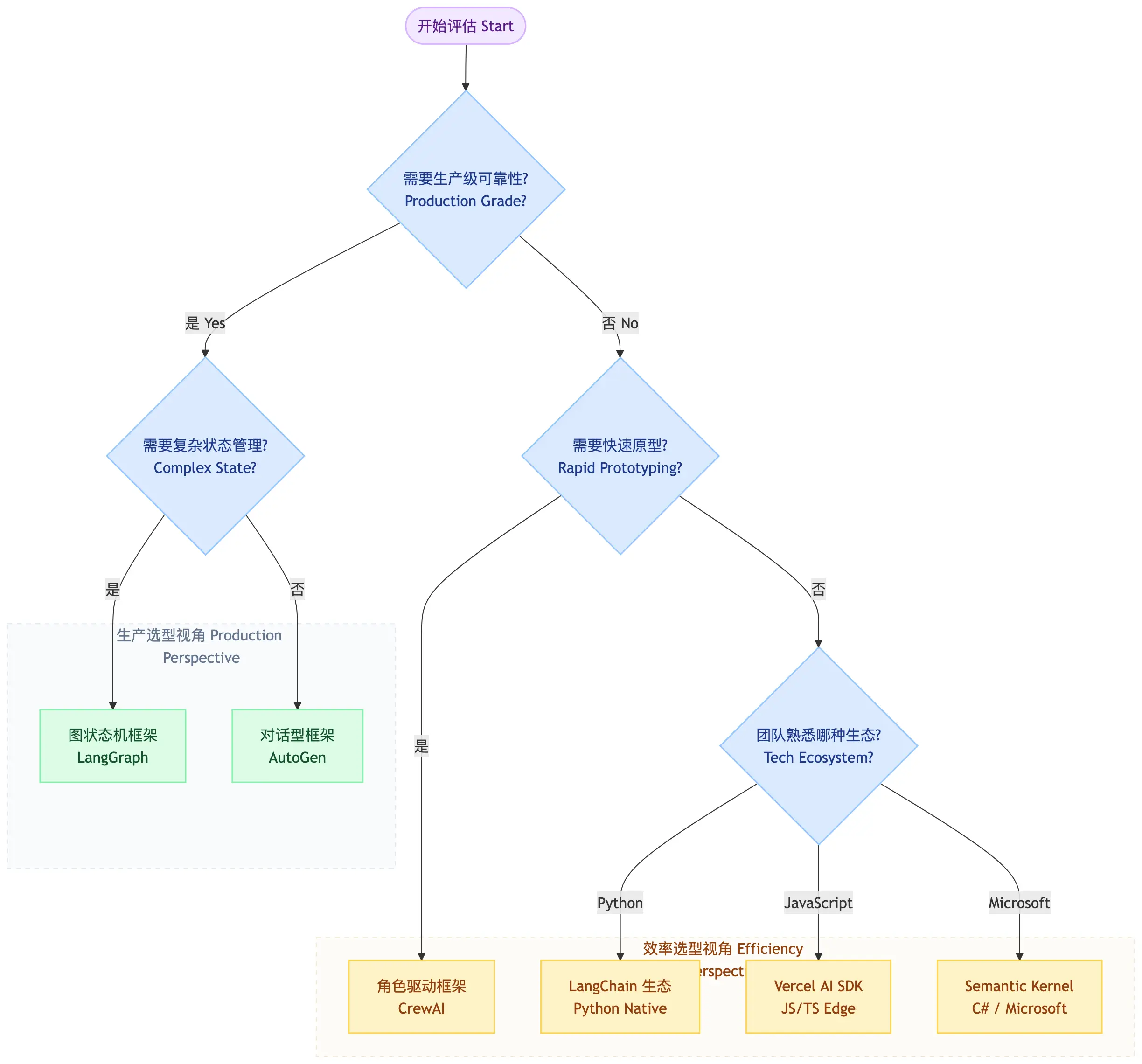
迁移路径建议:
- CrewAI原型 → LangGraph生产
- LangChain → LangGraph(状态管理升级)
- 自定义 → 选择性采用框架组件
核心理念:框架是工具,不是目标。先理解设计模式,再选框架。
8. 最佳实践清单
8.1 设计原则
- 显式优于隐式:工具调用、状态变更必须显式
- 失败快速终止:遇到无法恢复的错误立即停止
- 可观测性内置:每个关键决策点都应被记录
- 评估驱动开发:先定义评估标准,再实现功能
- 渐进式复杂度:从简单流程开始,逐步增加复杂度
8.2 实施建议
- 工具Schema第一:花时间设计高质量的工具描述
- 边界条件优先:首先处理错误和边缘情况
- 人工介入设计:预先设计何时需要人工确认
- Checkpoint策略:根据流程长度选择合适的持久化策略
- 评估指标体系:建立多层次的质量监控
结语
“模型质量曾是护城河,现在Agent Harness才是。”
构建一个可靠的Agent Harness,比选择更好的模型更能决定产品的成败。它需要数千小时的工程打磨,需要在Tool Router、State Manager、Evaluator、State Machine等各个环节精雕细琢。
但这其实是好事——护城河变深了。那些愿意在Harness上下功夫的团队,将建立起真正的竞争优势。