全同态加密在AI/机器学习中的应用:LatticaAI HEAL 底层硬件抽象层
引言
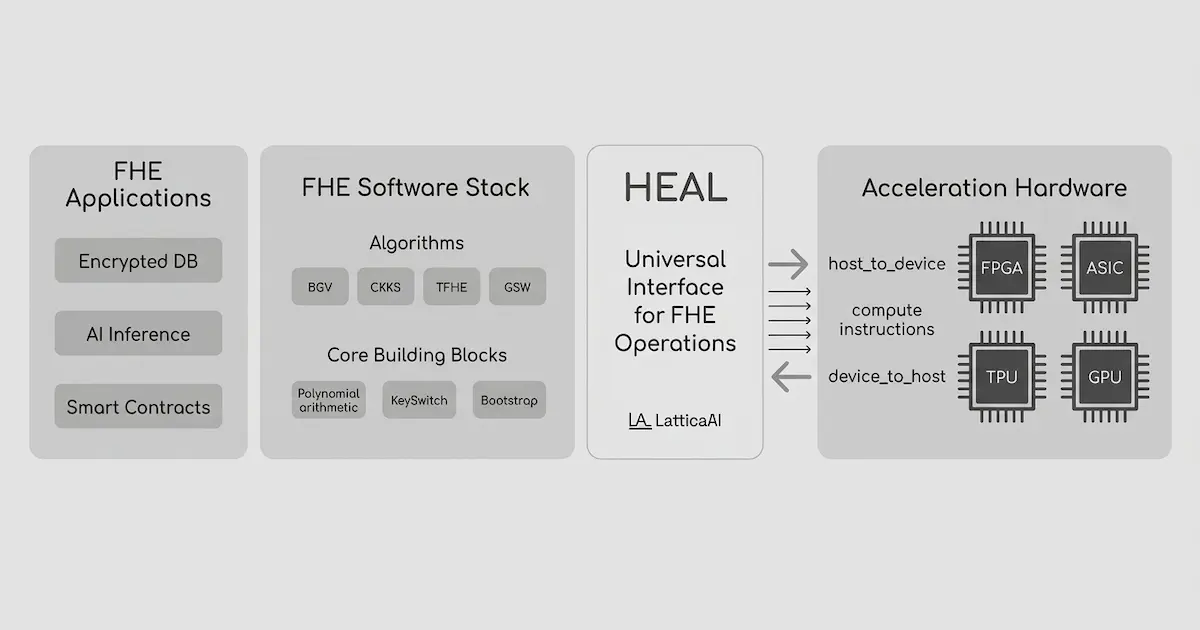
在隐私保护计算(Privacy-Preserving Computation)领域,全同态加密(FHE)正经历从算法突破向工程落地的关键跨越。对于 FHE 研究者而言,2025 年的核心命题已不再是“如何设计一个新的格密码方案”,而是“如何构建一个软硬协同的计算架构”。
本文将深入探讨处于技术前沿的初创公司 LatticaAI 的技术栈和平台。分析 LatticaAI 如何通过其 HEAL 框架定义了“标准化的硬件加速 AI 负载”。
LatticaAI:硬件抽象层 HEAL 的标准化之路
LatticaAI 的核心产物 HEAL (Homomorphic Encryption Abstraction Layer) 旨在打破 FHE 软件与硬件之间的壁垒。如果说 FHE 是隐私 AI 的引擎,那么硬件加速器(GPU/FPGA/ASIC)则是为引擎添加了涡轮增压器。然而,长期以来不同的 FHE 库(如 OpenFHE, SEAL)与异构硬件之间缺乏统一接口,甚至参数选取和实现细节也千差万别。这为提高 FHE 的行业采用率带来了重重困难,如:
- 怎么在加密数据上开发和部署 AI 模型推理负载?
- 使用什么 FHE 库作为应用编程接口编写应用?
- 不同的加速硬件使用什么标准可以保持兼容和互操作性?
在Python生态中,NumPy的多维数组(ndarray)是高效进行大量数学计算的标准抽象。传统的机器学习Scikit-learn和统计库Pandas都构建在NumPy数组上。
在进入深度学习后,NumPy 只支持 CPU 实现的数组已经无法满足计算量的激增的要求,采用GPU加速的Tensor实现成为必选项。PyTorch的Tensor提供了一个GPU上替换 NumPy数组的实现。至今,PyTorch 已经是事实上的行业标准,尤其在深度神经网络模型。
Tensor 相关的操作和计算接口可以很容易沿用现有的技术栈和实践,让机器学习和 AI 工程师无需关注底层硬件特性和 FHE 方案的细节,也让 FHE 研究者和硬件加速器开发者提供高层次的抽象。
1. 为什么需要 HEAL?
长期以来,不同的 FHE 库(如 OpenFHE, SEAL, Lattigo)与硬件加速器(GPU, ASIC)之间缺乏统一标准。LatticaAI 提出的 HEAL 层将复杂的密文运算抽象为标准化的 Tensor 算子,使开发者无需为每种硬件重写密码学逻辑。
2. 加密数据推理和加密计算调度
针对 CKKS 方案,Lattica 在 C++/Torch 层面重载了密文运算内核。通过 Double-CRT 表示,在大规模加密数据上运行 Transformer 模型时,Batch Size 的增加并不会导致延迟等比例上升。
HEAL 将复杂的密文多项式运算抽象为标准化的 Tensor 算子。这使得 AI 模型开发者无需理解底层的 RNS 分解或 NTT 变换,即可在各种硬件上调度密文计算资源。它是隐私 AI 负载从“实验室 CPU 环境”走向“生产级 GPU/ASIC 集群”的通行证。
3. HEAL 适配硬件加速器
对于 FHE 研究者和硬件加速器开发者而言,HEAL 的真正价值在于它定义了一套清晰的硬件接入标准。要为新的 ASIC/FPGA/GPU 加速器添加支持,开发者需要实现以下核心组件。
API 契约
HEAL 定义了一组需要硬件加速器厂商实现的头文件,位于include/中,作为上层算法和底层硬件能力的接口。
| 头文件 | 声明的结构和方法 |
|---|---|
include/device_memory.h | zeros(), empty(), contiguous(), host_to_device(), device_to_host() |
include/modular_ops.h | modmul_ttt/ttc/tct/tcc, modsum_ttt/ttc/tct/tcc, mod_tt/tc/ct, modneg_tt/tc |
include/modular_axis_sum_ops.h | axis_modsum(), modmul_axis_sum() |
include/ntt.h | ntt(), intt() |
include/gadget_decomposition.h | apply_g_decomp_relative_to_full_q() (all four type variants) |
include/tensor_layout_ops.h | reshape, moveaxis, expand, flatten, squeeze, unsqueeze, get_slice |
include/tensor_value_ops.h | set_const_val(), pad_single_axis(), take_along_axis() |
include/shape.h | Shape/stride utilities used across operations |
include/device_tensor.h | DeviceTensor<T> class template (central data structure) |
HEAL 代码库中提供了样例实现,位于example_impl/。
核心数据结构:DeviceTensor
一切从 DeviceTensor<T> 开始。这是 HEAL 唯一的前向声明——你需要为自家硬件完全实现这个类。它代表了存储在设备内存中的多维张量,必须包含维度 (dims)、步长 (strides) 和数据指针 (data),以及支持 broadcast 感知的元素访问方法。
参考 CPU 实现可以看到完整的接口契约:构造函数、元数据查询 (numel(), is_contiguous())、以及索引操作 (at(), at_with_broadcast())。特别重要的是使用 shared_ptr<void> 管理数据生命周期,这允许零拷贝的切片视图操作。
内存管理层(5个函数)
最基础的层次是主机与设备间的数据搬运。你需要实现:
zeros<T>和empty<T>:在设备上分配零初始化和未初始化的张量contiguous<T>:确保张量在内存中连续存储(如已连续则返回自身)host_to_device<T>和device_to_host<T>:PyTorch 张量与设备间的双向传输
模运算层(13个函数)
这是 FHE 计算的核心密集区。HEAL 将模运算细分为多个变体以优化不同场景:
- 模乘,有四个变体:
modmul_ttt(三个张量输入)、modmul_ttc(模数为标量)、modmul_tct(操作数为标量)、modmul_tcc(双标量)。这种设计允许编译器根据常量优化生成不同的内核路径。 - 模加,同样有四个对应的
modsum_*变体。 - 模余,操作 (
mod_tt/tc/ct) 和 模取反 (modneg_tt/tc) 则处理更基础的数论运算。
所有这些函数都是模板化的,典型实例化类型为 int8_t、int32_t 和 int64_t——对应 RNS 表示中不同位宽的分量。
张量布局操作(7个函数)
这部分有趣之处在于它们都是零拷贝的,这意味着即使是性能敏感的代码路径也可以频繁调用这些操作。主要包括:
expand通过设置 stride 为零实现虚拟广播;squeeze和unsqueeze只修改元数据;flatten、moveaxis、get_slice和reshape都是视角转换,不触发实际内存搬运。
数论变换 NTT/INTT(2个函数)
ntt 和 intt 是 FHE 多式运算的核心。HEAL 的 API 设计支持可选的 Barrett 预计算参数 (log2p_list, mu_list),这对于追求极致性能的硬件实现至关重要——你可以预计算这些常数并存储在快速片上内存中。
ntt 和 intt 的 API 设计支持可选的 Barrett 预计算参数(通过log2p_list和mu_list)。输入形状支持 [l, m, r, k] 或 [l, r, k, m]布局,,其中 m 是变换维度,k 是 RNS 模数数量。axis 参数指定变换轴,skip_perm 允许跳过位反转置换步骤(当数据已经预置位时)。允许硬件实现根据 RNS 模数数量 k 优化片上存储。
工具分解与轴约简
apply_g_decomp_relative_to_full_q 实现 RNS 到工具分解(Gadget Decomposition)的转换,这是重线性化密钥操作的基础。modmul_axis_sum 则是加密矩阵乘法的核心——它执行模乘-累加约简,并且累积到输出张量中(多次调用会叠加结果),这个设计在实现密文-明文乘积时非常高效。
在密码学领域,Gadget Decomposition 特指一种用于辅助构造或优化方案的技术组件,如 FHE 中常见的重现性化密钥。如果正好选取的是二进制位,则特化为比特分解(Bit Decomposition)。
例如,若值 的最大位宽是 ,若选取工具基(Gadget Base) ,其中,那么 可以分解为
Python 绑定层
HEAL 使用 pybind11 将 C++ API 暴露给 Python。在 py_bindings.cpp 中,你需要为每个数据类型绑定操作,以及多类型函数(如 NTT 的 <int8_t, int32_t> 组合)。好消息是,这部分通常不需要修改——只要你实现了 C++ 模板特化,绑定层会自动处理。
测试验证
HEAL 的tests/中包含了ctest的C++单元测试。在实现了硬件加速器的API后,需修改链接目标到新加的代码,通过CTest运行测试。测试覆盖了所有的操作,包括NTT、模运算、工具分解、Tensor 操作等。
除此之外,如果增加新加速器实现后构建了lattica_hw模块,还可以通过Python脚本执行全流程验证,如 MNIST 数字识别模型推理等已经添加到examples_transcripts/下的加密模型负载。
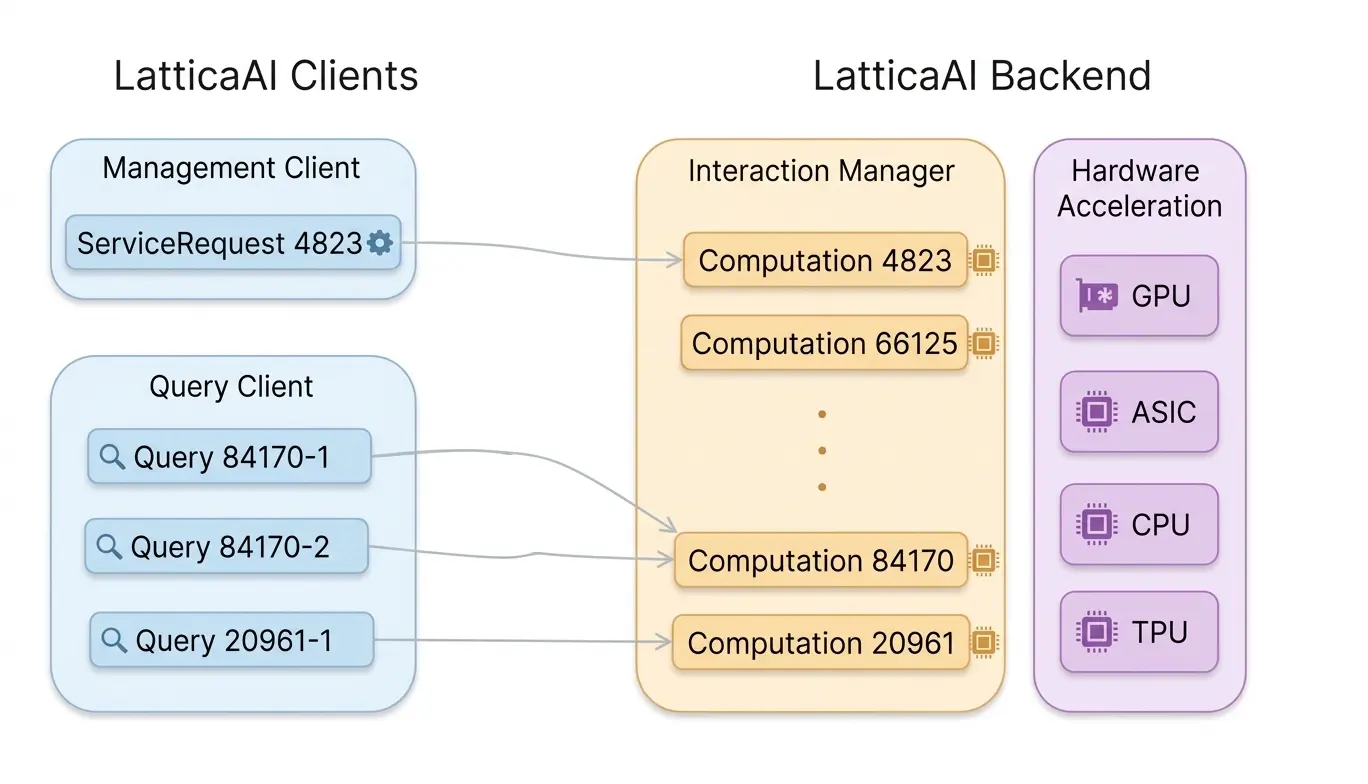
LatticaAI FHE即服务平台
LatticaAI 的主要商业模式是按量收费的 FHE 即服务(FHE-as-a-Service)平台,允许用户上传模型、调用硬件加速的加密数据推理服务。
- 平台的最底层是构建在 HEAL 之上的异构加速硬件,当前主要是 GPU。
- LatticaAI 维护加密算力后端服务,包括访问控制、费用计量、模型转换、访问API端点等服务。
- 加密AI模型或加密计算程序通过管理客户端处理模型的上传、启用等,而加密AI模型或计算程序的用户通过查询客户端调用平台的加密数据计算能力,并支付费用。
管理加密模型或计算
lattica-management提供LatticaManagement.upload_model_file()和LatticaManagement.upload_plain_model()两个方法用于模型上传,可以同时处理PyTorch模型或Sunscreen的ELF文件。
def upload_plain_model(self, model_file_path, model_id):
self.http_client.send_http_file_request(
'api/files/upload_non_homomorphic_model',
req_params={'modelId': model_id},
model_file_path=model_file_path
)
def upload_model_file(self, model_file_path, model_id, homomorphic_params):
key = self.agent_app.upload_file(model_file_path, endpoint='api/model/get_model_upload_url',
req_params={'modelId': model_id})
alert_upload_complete = self.agent_app.alert_upload_complete(key, homomorphic_params)
print(f"Model {model_id} uploaded status is {alert_upload_complete}.")真正的模型上传请求由lattica-common提供,相关的代码。
class LatticaAppAPI:
def __init__(self, account_token: str):
self.http_client = HttpClient(account_token, module_name="lattica_common")
# ============== start API calls ============== #
def upload_file(self, file_path: str, endpoint: str, req_params: Optional[dict] = None) -> str:
response = self.http_client.send_http_request(endpoint, req_params)
upload_url = response['s3Url']
file_size = os.path.getsize(file_path)
print(f"Uploading file ({file_size / 1024 ** 2:.1f} MB)...")
if file_size == 0:
# To avoid: header (Transfer-Encoding: chunked) that S3 does not support for pre-signed PUT uploads.
res = requests.put(upload_url, data=b'')
else:
with open(file_path, "rb") as file:
res = requests.put(upload_url, data=file)
res.raise_for_status()
return response['s3Key']LatticaAI发布了闭源的lattica-management管理客户端,用于上传、启用模型等。管理客户端使用纯Python实现,并没有相应的模型权重处理代码,模型的隐私处理由LatticaAI平台处理,可能导致泄漏。
调用加密AI模型推理或计算
调用加密AI模型推理或计算通过lattica-query完成。基本步骤如下:
- 一次性的密钥生成,用于加密查询参数、解密计算结果;
- 按需持续的加密查询和结果处理。
集成Sunscreen Parasol的TFHE 加密计算负载
在拥有了 HEAL 这一算力底座后,LatticaAI 的核心优势体现在其对托管的生产级加密AI推理。LatticaAI 的托管加密计算支持 GPU 加速的 CKKS 方案。近期与Sunscreen的合作也可以支持通过Sunscreen Parasol 编译器带来的 TFHE 加密计算负载。
LatticaAI 官方的文档“TFHE End-to-End Demo (Sunscreen + Lattica)”有调用Sunscreen的TFHE加密计算负载的详细步骤。
1. 原生 CKKS 大规模张量推理
针对卷积神经网络(CNN)等深度学习模型,LatticaAI 利用 HEAL 的张量算子,在 GPU 上对 CKKS 方案进行了深度优化。通过 Double-CRT 表示,它实现了大规模加密数据的批处理(SIMD),确保了 Batch Size 增加时延迟的非等比例增长,是高吞吐量密文推理的首选。
2. Sunscreen Parasol 编译器的 TFHE
根据 LatticaAI 的调研报告,TFHE 以其快速自举和全面的运算支持成为需求最大全同态密码方案。LatticaAI 通过支持 Sunscreen Parasol 编译的 TFHE 加密计算负载增加了对 TFHE 的支持。
Sunscreen推出的Parasol是一个虚拟的处理器架构,并有从LLVM分叉处的Parasol编译器支持自定义的parasol目标ELF二进制文件。Parasol编译器生成的ELF二进制文件目前可以通过虚拟的Parasol CPU和运行时执行。Sunscreen 扩展Parasol到面向Web3开发的SPF(Secure Processing Framework)框架。
3. 调用 TFHE 计算负载
LatticaAI提供两个Python包客户端,用于发送调用请求,分别是
- lattica-query,包含
lattica-fhe-core后端,支持GPU加速。 - lattica-query-sunscreen,包含
sunscreen-fhe后端,仅支持CPU执行。
新增的lattica-query-sunscreen客户端调用托管在 LatticaAI 平台上的加密计算资源。
结语:隐私 AI 的工程化终局
LatticaAI 的路径展示了一个清晰的工程终局:FHE 不再只是密码学研究的对象,而扩展成一个成熟的软件工程栈,为进入生产级应用做好准备。
随着 HEAL 确立了硬件接入的“最后十米”标准,隐私 AI 正在进入“全栈交付”时代。对于 FHE 研究者和 AI 工程师而言,未来的工作重心将是:如何在这套稳固的硬件抽象与负载路由架构之上,构建真正具备“模型隐私、逻辑验证、高吞吐”特性的下一代可信 AI 计算负载。