全同态加密在AI/机器学习中的应用:CipherFlow LattiSense 框架和 LattiAI 平台
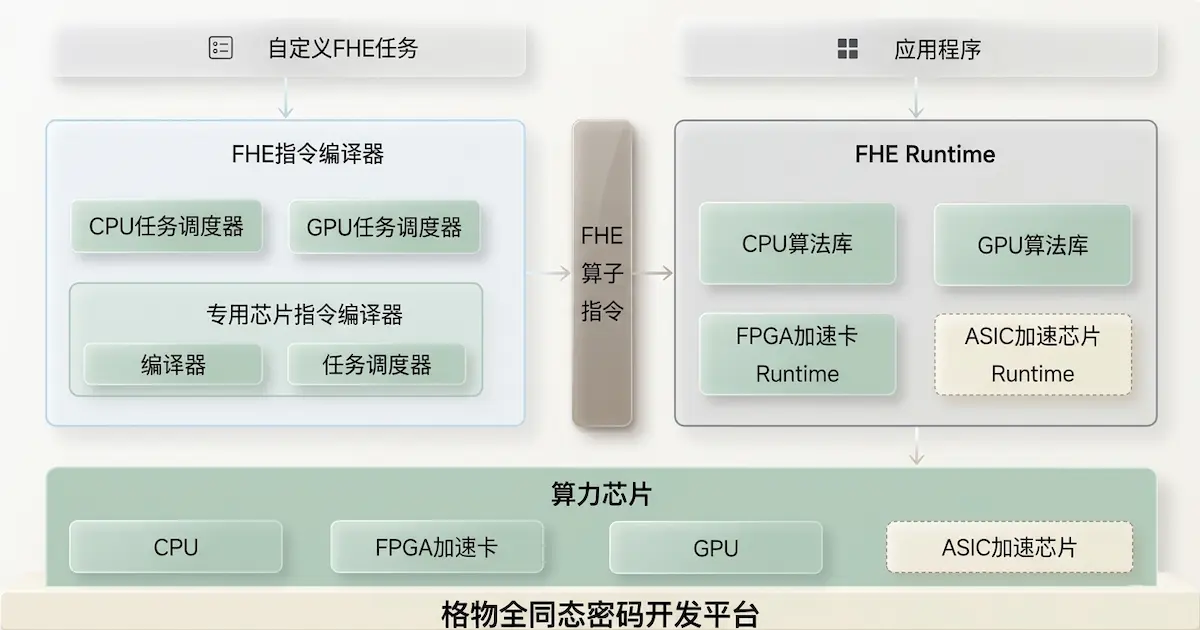
引言
在全同态加密(FHE)技术从学术研究走向工程落地的过程中,一个清晰的挑战始终摆在研究者面前:如何构建一个真正生产就绪的全栈框架?传统的 FHE 生态中,加密库(SEAL、OpenFHE)、编译器(HEIR、Concrete)、调度器(TFHE-rs)、硬件加速器各自为政,开发者需要在不同工具链之间反复切换,严重阻碍了 FHE 的实际应用。
本文将深入分析 CipherFlow 的开源技术栈——LattiSense(FHE开发框架)和LattiAI(隐私保护AI推理平台)。与 LatticaAI 的 HEAL 硬件抽象层不同,CipherFlow 选择了一条全栈整合的路径:从 Python 前端计算图定义,到 C++ 运行时执行,再到编译器自动优化和异构硬件调度,构建了一个完整的垂直技术栈。
对于 FHE 研究者而言,CipherFlow 最值得关注的技术创新是其Generalized Interleaved Packing (GIP)方案——这一突破性工作解决了高分辨率图像在 FHE 计算中的打包瓶颈,使得任意分辨率的端到端加密推理成为可能。
LattiSense:全栈 FHE 开发框架
LattiSense 的核心设计理念是计算任务定义与运行时执行的完全解耦。开发者通过 Python 前端定义抽象计算图,编译器自动优化生成执行指令,运行时调度器根据硬件配置(CPU/GPU/FPGA)动态选择最优后端。
1. 架构定位:整合四类工具
在传统 FHE 生态中,开发者需要组合使用多类工具:
| 传统分类 | 代表项目 | LattiSense 整合方案 |
|---|---|---|
| 加密库 | SEAL, OpenFHE, TFHE-rs, Lattigo | 集成 Lattigo和HEonGPU作为CPU和GPU后端 |
| FHE 编译器 | HEIR, Concrete | Python 前端计算图编译器 |
| FHE 调度器 | LatticaAI, HLG | mega_ag_runners 运行时调度器 |
| 硬件加速器 | Zama HPU, HERACLES | HEonGPU(GPU)+ 可扩展 FPGA/ASIC 接口 |
LattiSense的定位是整合业界最佳的外部密码库(best-in-class external cryptographic libraries)、支持专有的硬件加速的全栈框架。LattiSense的主要组件、实现方式和功能如下表。
| 层级 | 实现 | 主要组件 | 功能 |
|---|---|---|---|
| 前端 | Python | frontend/custom_task/和mega_ag_generator/ | 高层次FHE任务定义和编译 |
| SDK | C++ | cxx_sdk_v2/及cxx_fhe_task.h | 任务加载、验证和编排 |
| 执行引擎 | C++/CUDA | mega_ag_runners/ | 计算图解析和执行 |
| 密码后端 | Go/CUDA | fhe_ops_lib/和HEonGPU/ | 底层密码原语实现 |
2. Python 前端:计算任务定义
LattiSense 的 Python 前端提供了一套声明式 API,开发者只需描述计算逻辑,无需关心底层实现细节。
# 1. 设置 FHE 参数
from frontend.custom_task import *
param = Param.create_bfv_default_param(n=16384)
set_fhe_param(param)
# 2. 定义输入密文节点
level = 2
x = BfvCiphertextNode('x', level)
y = BfvCiphertextNode('y', level)
# 3. 定义计算任务(乘法+重线性化)
z = mult_relin(x, y, 'z')
# 4. 生成执行指令
process_custom_task(
input_args=[Argument('x', x), Argument('y', y)],
output_args=[Argument('z', z)],
output_instruction_path='examples/quick_start',
)关键设计:
- 节点类型系统:
BfvCiphertextNode、CkksCiphertextNode、BfvPlaintextNode等不同节点类型 - 层级追踪:编译器自动计算每个节点的密文层级(
level),防止噪声溢出 - 操作符重载:
mult_relin自动插入重线性化操作
LattiSense声明式构建ERG的方式,借鉴了TensorFlow的开发体验(没有整合Keras之前)。通过逐级声明节点和连接关系,并对每一个节点赋予一个名称,最终把输入和输入作为参数传递到process_custom_task()中编译、生成编译后的任务执行指令。
process_custom_task()中支持额外的参数fpga_acc开启或禁用FPGA加速后端。
3. C++ 运行时:MegaAG 执行图
编译器生成的MegaAG(Multiply-Add Graph)是 LattiSense 的核心抽象。它是一个有向无环图(DAG),描述了完整的计算流程:
struct DatumNode {
NodeIndex index;
std::string id;
std::vector<ComputeNode*> successors;
bool is_output;
DataType datum_type; // TYPE_CIPHERTEXT, TYPE_PLAINTEXT
int32_t level; // 密文层级
int32_t degree; // 密文度数 (2 或 3)
bool is_ntt; // NTT 形式标志
bool is_mform; // 乘法形式标志
};
struct ComputeNode {
NodeIndex index;
std::string id;
std::vector<DatumNode*> input_nodes;
std::vector<DatumNode*> output_nodes;
ExecutorFunc executor; // 统一执行器函数
OperationType op_type; // ADD, SUB, MULTIPLY, ROTATE, etc.
};
struct MegaAG {
std::unordered_map<NodeIndex, DatumNode> data;
std::unordered_map<NodeIndex, ComputeNode> computes;
std::vector<NodeIndex> inputs;
std::vector<NodeIndex> outputs;
Processor processor; // CPU, GPU, FPGA
};执行流程:
- 拓扑排序:基于
successors依赖关系确定执行顺序 - 动态就绪检测:
get_available_computes()找出可并行执行的节点 - 引用计数清理:
purge_unused_data()自动释放中间结果 - 硬件透明切换:通过
Processor枚举选择执行后端
4. 硬件抽象层:统一执行器接口
LattiSense 的硬件抽象层设计堪称精妙。所有硬件后端(CPU、GPU、FPGA)都实现相同的执行器签名:
using ExecutorFunc = std::function<void(
ExecutionContext& ctx, // 硬件上下文
const std::unordered_map<NodeIndex, std::any>& inputs, // 输入数据
std::any& output, // 输出数据
const ComputeNode& self // 节点元信息
)>;CPU 执行器实现:
ExecutorFunc cpu_add_executor = [](ExecutionContext& ctx,
const auto& inputs,
std::any& output,
const ComputeNode& self) {
// 1. 提取 CPU 上下文
auto& ckks_ctx = ctx.get_context<CkksContext>();
// 2. 提取输入密文
const auto& ct1 = std::any_cast<const CkksCiphertext&>(
inputs.at(self.input_nodes[0]->index));
const auto& ct2 = std::any_cast<const CkksCiphertext&>(
inputs.at(self.input_nodes[1]->index));
// 3. 执行 CPU 加法
output = ckks_ctx.add(ct1, ct2);
};GPU 执行器实现(相同的函数签名):
ExecutorFunc gpu_add_executor = [](ExecutionContext& ctx,
const auto& inputs,
std::any& output,
const ComputeNode& self) {
// 1. 提取 GPU 算子上下文
auto& he_op = ctx.get_context<HEOperator<Scheme::CKKS>>();
// 2. 提取输入密文(GPU 设备内存)
const auto& ct1 = std::any_cast<const Ciphertext<Scheme::CKKS>&>(
inputs.at(self.input_nodes[0]->index));
const auto& ct2 = std::any_cast<const Ciphertext<Scheme::CKKS>&>(
inputs.at(self.input_nodes[1]->index));
// 3. 提取执行选项(CUDA 流)
auto* opts = ctx.get_other_arg<ExecutionOptions>(0);
// 4. 执行 GPU 加法
Ciphertext<Scheme::CKKS> result;
he_op.add(ct1, ct2, result, opts ? *opts : ExecutionOptions());
output = result;
};关键技术:
std::any类型擦除:统一处理不同硬件的密文/明文类型Processor枚举:编译时或运行时动态选择后端- 零拷贝切换:相同的 MegaAG 可在 CPU/GPU/FPGA 上执行
LatticaAI 的 HEAL 框架专注于硬件抽象层的标准化,定义了一套清晰的 API 契约供加速器厂商实现。而 LattiSense 选择自研全栈,不仅提供了硬件抽象层,还实现了完整的编译器、调度器和算子库。两种路径各有优势:HEAL 更适合生态共建,LattiSense 更适合垂直整合。
5. CPU 后端:Lattigo 集成
LattiSense通过CGo绑定Go语言实现的Lattigo库,作为默认的CPU后端。此外,通过设置LATTISENSE_BUILD_SEAL_PLUG_IN参数也可以支持微软SEAL后端,在特定场景下性能可能由于Lattigo。
在LattiSense中,使用CPU后端也称之为“同构模式”(Homogeneous Mode)。这种执行模式下,所有的FHE对象如BfvCiphertext和CkksContext都在CPU上进行,没有内存数据的跨边界搬运,任务编译到FheTaskCpu类对象上。
6. GPU 加速:HEonGPU 集成
LattiSense 通过集成 HEonGPU(fork 自 Alisah-Ozcan/HEonGPU)实现了完整的 GPU 加速栈。HEonGPU 不仅提供了 CUDA 内核实现,还集成了三个关键的 GPU 加速库:
| 组件 | 功能 | 性能提升 |
|---|---|---|
| GPU-NTT | 快速数论变换(多项式乘法核心) | 50-76x |
| GPU-FFT | 快速傅里叶变换(CKKS 编码) | 5-20x |
| RNGonGPU | GPU 随机数生成 | 100-1000x |
性能对比(MobileNetV2 ImageNet 推理):
| 硬件 | 延迟 | 加速比 |
|---|---|---|
| 16 线程 CPU | 1210.0s | 1x |
| GPU (RTX 4090) | 82.4s | 14.7x |
GPU和FPGA加速后端,在LattiSense中又称为“异构模式”(Heterogeneous Mode)。在此模式下,FHE对象转化成C兼容句柄,数据需要在主机和设备间传输,通过CUDA streams或设备特定的方式支持异步执行,任务编译到FheTaskGpu和FheTaskFpga类对象上。
主流的支持GPU加速的TFHE实现中,TFHE-rs是一个重要的参照对象(参见TFHE-rs深度解析之一:总览)。TFHE-rs最重要的架构考虑是基于“客户端-服务器”的架构:
- 客户端生成密钥、加密和解密,以及生成和验证ZK-POK证明。除此之外,加密比特串(strings)和密文比特串(encrypted strings)也在客户端完成。客户端的操作都在CPU上完成。
- 服务端加载服务端密钥(server key),支持密文逻辑和算术运算。这些操作通常运行在GPU后端上,并从性能考虑使用了稍微不同的参数。此外GPU实现也只支持压缩的服务端密钥,压缩密文与CPU后端也不尽相同。
HEonGPU的设计则采用了“all-in-on-the-GPU”哲学,即尽可能长时间保持所有操作都在GPU上进行,除非显式把数据流控制交还到CPU。因此,HEonGPU实现了密钥生成、消息编解码、加密和解密、密文运算和密钥切换等。这里最基本的假定即是:所有的运算和操作都在同一台主机的CPU和GPU之间协同,而不是“客户端-服务器”架构。
然而,HEonGPU实现的TFHE仅支持密文逻辑运算(AND、OR、XOR等)。后面我们会看到,神经网络中的非线性单元如ReLU不能使用TFHE算法,因为不支持密文算术运算。而TFHE-rs通过多种机制(消息/进位编码、PBS刷新进位、大整数基分解表示)扩展了TFHE算法,同时支持算术运算和逻辑运算。
启用GPU加速后端需要额外的编译参数LATTISENSE_ENABLE_GPU(默认禁用)和LATTISENSE_CUDA_ARCH(默认空)。先编译HEonGPU,并安装到代码库的HEonGPU/install下。
# 在HEonGPU目录,配置构建
cmake -S . -B build -DCMAKE_CUDA_ARCHITECTURES=86 -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=$(pwd)/install
# 编译
cmake --build ./build/ -j$(nproc)
# 安装到HEonGPU/install下
cmake --install .然后在LattiSense代码库,启用LATTISENSE_ENABLE_GPU和LATTISENSE_CUDA_ARCH参数,编译代码。
# 在主目录下,启用GPU加速配置构建
cmake -S . -B build -DCMAKE_INSTALL_PREFIX=$(pwd)/install \
-DLATTISENSE_BUILD_EXAMPLES=ON \
-DLATTISENSE_BUILD_TESTS=ON \
-DLATTISENSE_ENABLE_GPU=ON -DLATTISENSE_CUDA_ARCH=86
# 编译
cmake --build ./build/ -j$(nproc)
# 运行build/bin/example和build/bin/benchmark下的样例和性能测试
# 部分测试需要运行相应的Python脚本构造测试数据编译过程中,使用文档中的CUDA Toolkit版本12.0可能遇到错误:/path/to/HEonGPU/install/include/fmt/format.h(4424): error: a literal operator template must have a template parameter list equivalent to "<char ...>"。这是12.0版以前nvcc的已知问题,升级CUDA Toolkit到12.3以上的版本可以解决。
此外,可能在src/include/common/common.ch还会报错namespace "std" has no member "uint64_t",修改头文件,增加#include <cstdint>可以解决。
Google Colab免费提供Nvidia T4 GPU(比较旧的Turing架构),可以测试HEonGPU的性能。相关的Jupyter Notebook参见这个Gist。
7. FPGA 加速:专有加速硬件
LattiSense代码库中引用了私有的代码库cipherflow-fhe/lattisense-lib-fpga,作为FPGA加速的密码实现。由于代码没有公开,暂时无法分析和测试。
LattiAI:隐私保护 AI 推理平台
LattiAI目前提供CNN、ResNet、MobileNet等模型的训练、微调和加密推理,对于新的模型架构如Transformer没有支持。核心优化GIP是对图片数据打包,并且RangeNormPoly2d提供二维图像数据的支持。
LattiAI 是构建在 LattiSense 之上的端到端 FHE AI 推理框架。它的核心创新在于解决了高分辨率图像在 FHE 计算中的打包瓶颈——Generalized Interleaved Packing (GIP)方案。
1. GIP 方案:突破高分辨率瓶颈
问题背景
传统的 FHE 打包方案(如 Gazelle 的 Continuous Packing)在处理高分辨率图像时面临根本性限制:
- 槽位容量有限:CKKS 方案的单个密文槽位容量为 N/2(如 N=16384 时为 8192)
- 高分辨率超限:224×224 图像的单通道像素数(50176)远超槽位容量
- 算子兼容性差:在通道边界处理时,传统打包方案的卷积、池化算子难以正确实现
GIP 核心思想
引入通道打包因子(Channel Packing Factor):
其中:
- :图像空间分辨率
- :基础打包大小(不超过 CKKS 槽位容量)
自适应打包策略:
| g 值 | 打包策略 | 适用场景 |
|---|---|---|
| g = 1 | Continuous Packing | 标准分辨率 |
| g < 1 | Multiplexed Packing | 通道交错 |
| g > 1 | GIP 分解(创新) | 高分辨率图像 |
GIP 分解算法(g > 1)
当图像分辨率超过槽位容量时,GIP 将每个通道分解为 个交错子通道:
// 输入:H×H×C 的特征图,g = H/Ĥ
// 输出:g² 个 Ĥ×Ĥ×C 的子特征图
for (int c = 0; c < C; c++) {
for (int i = 0; i < g; i++) {
for (int j = 0; j < g; j++) {
// 提取交错子通道
for (int y = 0; y < Ĥ; y++) {
for (int x = 0; x < Ĥ; x++) {
int src_y = i * Ĥ + y;
int src_x = j * Ĥ + x;
sub_channel[i*g+j][c][y*Ĥ+x] = input[c][src_y*H+src_x];
}
}
}
}
}技术价值:
- 支持任意分辨率图像的端到端加密推理
- 保持加密算子的打包格式兼容性
- SIMD 并行效率不损失
- 为卷积操作提供了统一的抽象
2. 完整推理 Pipeline
LattiAI 的推理 Pipeline 包含三个阶段:模型适配 → 模型编译 → 加密推理。
阶段一:模型训练和适配
优先通过训练脚本在明文下训练一个精确的模型,这一步不涉及FHE算子。
# CIFAR-10 ResNet20
python train.py \
--epochs 200 \
--batch-size 128 \
--lr 0.1上面的训练完后,导出的模型还需要通过添加--poly_model_convert替换CKKS不支持的ReLU、SiLU、MaxPooling等算子成近似,并额外训练几个epoch微调调换算子带来的损失变差。
python train.py \
--poly_model_convert \
--pretrained train_baseline.pth \
--degree 4 \
--upper-bound 3.0 \
--poly-module RangeNormPoly2dLattiAI官方白皮书提到通过真正的ReLU和MaxPooling等非线性算子上训练,替换成FHE支持的非线性近似,并微调模型,最终的效果会比直接训练更好。另一个原因是计算量会稍大,但不会影响最终模型性能。
算子映射规则:
| 原始算子 | FHE 兼容算子 | 说明 |
|---|---|---|
| ReLU/SiLU | RangeNormPoly2d | 多项式近似(2/4 阶) |
| MaxPool | AvgPool | 平均池化替换(避免比较操作) |
| BatchNorm | 融合到卷积层 | 减少乘法深度 |
多项式近似激活函数:
class PolyReLU2D {
public:
// 使用 Chebyshev 多项式近似 ReLU
Feature2DEncrypted run(CkksContext& ctx,
const Feature2DEncrypted& input) {
// ReLU(x) ≈ Σ c_k * T_k(x),其中 T_k 是 Chebyshev 多项式
// 使用 Clenshaw 算法数值稳定求值
return evaluate_clenshaw(ctx, input, relu_coeffs_);
}
private:
std::vector<double> relu_coeffs_; // 预计算的多项式系数
};RangeNormPoly2d具有可学习的状态,支持2阶和4阶的埃尔米特多项式近似(Hermite Polynomial Approximation)ReLU和SiLU激活函数。原本的ReLU激活函数,在这里近似为:
其中,是ReLU的输入正规化的结果,如缩放到。
class Simple_Polyrelu(nn.Module):
"""Polynomial activation approximating ReLU or SiLU via Hermite expansion.
Exported as a single ``nn_tools::Simple_Polyrelu`` custom op in ONNX.
Args:
scale_before: Input scaling factor.
scale_after: Output scaling factor.
degree: Polynomial degree (2 or 4).
activation: Target activation ('relu' or 'silu').
"""
# Hermite coefficients for ReLU approximation
_RELU_COEFF = {
2: (0.39894228, 0.50000000, 0.28209479 / np.sqrt(2), 0.0, 0.0),
4: (0.39894228, 0.50000000, 0.28209479 / np.sqrt(2), 0.0, -0.08143375 / np.sqrt(24)),
}
# Coefficients for SiLU approximation
_SILU_COEFF = {
2: (0.20662096, 0.50000000, 0.24808519 / np.sqrt(2), 0.0, 0.0),
4: (0.20662096, 0.50000000, 0.24808519 / np.sqrt(2), 0.0, -0.03780501 / np.sqrt(24)),
} if degree == 2:
return a0 + (a1 + a2 * x) * x - a2
elif degree == 4:
return a0 + a1 * x + a2 * (x**2 - 1) + a4 * (x**4 - 6 * x**2 + 3)
else:
raise ValueError(f'Unsupported degree: {degree}')如果画出区间的ReLU激活函数和4届埃尔米特多项式近似,可以看出绿线部分的4阶埃尔米特多项式与黑色ReLU函数在附近已经非常接近。
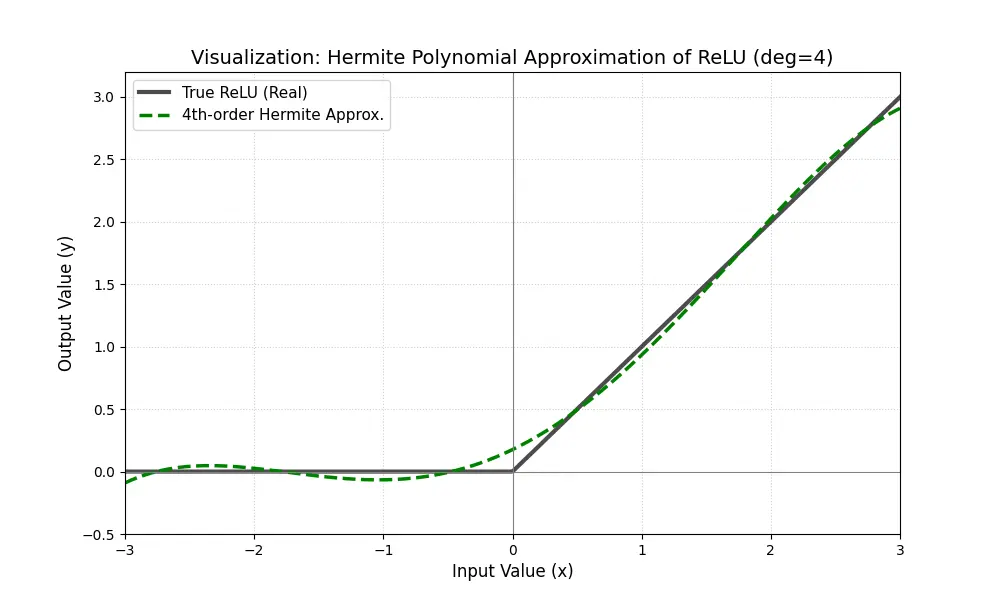
由于其简单的特性,ReLU是神经网络中使用最广泛的激活函数,通常计算 。然而对于CKKS等全同态加密的密文数据上的计算而言,ReLU的非线性需要比较输入和的大小,并不容易实现。
因此,在保护隐私的机器学习中,以的多项式在特定区间尽可能逼近ReLU的曲线是常见的方法。在众多可选的多项式构造中,埃尔米特多项式(Hermite Polynomials)具有以下的优势:
- 神经网络权重初始化,通常符合高斯分布,即值的范围集中在中心,而两边的比较少。埃尔米特多项式专门为高斯分布下的数据逼近设计,比其他构造方式精度更高。
- 不像ReLU在0点不可微分,埃尔米特多项式近似的ReLU在0点光滑可微。
阶段二:模型编译
将 ONNX 模型编译为 FHE 计算图(MegaAG):
python run_compile.py \
--input trained_poly.onnx \
--output ./runs/cifar10/ \
--style=multiplexed编译器功能:
- 自动选择 FHE 参数(N、模数链、缩放因子)
- 智能插入 Bootstrapping 节点(动态规划搜索最优刷新策略)
- 分配层级别(level)和缩放因子(scale)
- 生成 CKKS 兼容的 DAG 表示
阶段三:加密推理执行
// 客户端:加密输入
InferenceClient client("./task/client");
auto encrypted_input = client.encrypt("img.csv");
// 服务端:推理(选择硬件后端)
InferenceServer server("./task/server", use_gpu);
auto encrypted_output = server.evaluate(encrypted_input);
// 客户端:解密结果
auto result = client.decrypt(encrypted_output);3. 加密卷积实现
基于 GIP 方案,LattiAI 实现了三种加密卷积算法:
Continuous Packing 卷积(g = 1)
利用经典的 Gazelle 方法,通过同态旋转对齐输入元素:
Feature2DEncrypted run(CkksContext& ctx,
const Feature2DEncrypted& input) {
for (int i = 0; i < kernel_h; i++) {
for (int j = 0; j < kernel_w; j++) {
// 1. 旋转输入密文
int step = (i - center_y) * width + (j - center_x);
CkksCiphertext rotated = ctx.rotate(input, step);
// 2. 元素级乘法(密文 × 明文权重)
CkksCiphertext prod = ctx.mult_plain(rotated, weight[i][j]);
// 3. 累加求和
output = ctx.add(output, prod);
}
}
return output;
}Multiplexed Packing 卷积(g < 1)
利用通道交错特性并行计算多通道卷积:
Feature2DEncrypted run(CkksContext& ctx,
const Feature2DEncrypted& input) {
// 每个输入通道独立执行基本卷积
for (int c = 0; c < n_channels; c++) {
auto channel_result = basic_convolution(input.get_channel(c), kernel[c]);
// 通过旋转聚合到指定位置
channel_result = ctx.rotate(channel_result, c * stride);
// 重新打包为 Multiplexed 格式
output = multiplex_pack(output, channel_result);
}
return output;
}GIP 分解卷积(g > 1)— 核心创新
Feature2DEncrypted run(CkksContext& ctx,
const Feature2DEncrypted& input) {
// 1. 将每个通道分解为 g² 个交错子通道
std::vector<Feature2DEncrypted> sub_channels;
for (int i = 0; i < g; i++) {
for (int j = 0; j < g; j++) {
sub_channels.push_back(extract_sub_channel(input, i, j, g));
}
}
// 2. 对每个子通道执行步长为 g 的卷积
std::vector<Feature2DEncrypted> partial_results;
for (int idx = 0; idx < g * g; idx++) {
auto result = strided_convolution(sub_channels[idx], kernel, g);
partial_results.push_back(result);
}
// 3. 累加所有子通道结果
Feature2DEncrypted output = partial_results[0];
for (int idx = 1; idx < g * g; idx++) {
output = ctx.add(output, partial_results[idx]);
}
return output;
}4. 全连接层优化:对角线打包
全连接层本质上是矩阵-向量乘法。LattiAI 使用对角线打包方案优化:
// 权重矩阵按对角线方向打包为明文向量
// 主对角线:[w₀₀, w₁₁, w₂₂, w₃₃]
// 次对角线1:[w₀₁, w₁₂, w₂₃, w₃₀]
// ...
Feature2DEncrypted run(CkksContext& ctx,
const Feature2DEncrypted& input,
const WeightMatrix& weight) {
Feature2DEncrypted output = ctx.encrypt_zero();
for (int d = 0; d < n_diagonals; d++) {
// 1. 旋转输入密文
CkksCiphertext rotated = ctx.rotate(input, d);
// 2. 密文 × 明文对角线
CkksPlaintext diag_pt = encode_diagonal(weight, d);
CkksCiphertext prod = ctx.mult_plain(rotated, diag_pt);
// 3. 累加到输出
output = ctx.add(output, prod);
}
return output;
}5. 支持的模型架构
| 模型类型 | 代表模型 | 验证数据集 | 基线精度 | FHE 精度 |
|---|---|---|---|---|
| 图像分类 | ResNet-18/44 | CIFAR-10 | - | 接近基线 |
| MobileNetV2 | ImageNet | 71.8% | 70.1% | |
| 目标检测 | YOLOv5 | COCO | - | 验证中 |
技术对比与生态定位
与 LatticaAI HEAL 的对比
| 维度 | LatticaAI HEAL | CipherFlow LattiSense |
|---|---|---|
| 技术定位 | 硬件抽象层标准化 | 全栈 FHE 框架 |
| 核心产品 | HEAL API | LattiSense + LattiAI |
| 开源策略 | 闭源云服务为主 | Apache 2.0 开源 |
| 硬件支持 | GPU/TPU/CPU/ASIC/FPGA | CPU/GPU(FPGA 预留) |
| AI 优化 | 通用 FHE 计算 | GIP 方案专注 AI 推理 |
| 商业模式 | FHE-as-a-Service 云服务 | 开源 + 企业服务? |
与 Zama Concrete 的对比
| 维度 | Zama Concrete | CipherFlow LattiAI |
|---|---|---|
| 技术方案 | TFHE 为主 | CKKS 为主 |
| 硬件加速 | HPU on FPGA(已开源) | HEonGPU(GPU) |
| 目标市场 | 区块链 + AI | AI 推理(专注) |
| 融资情况 | $73M(估值 $400M) | 未披露 |
| 本土化 | 欧美团队 | 中国团队 |
技术成熟度评估
| 组件 | CipherFlow | LatticaAI | Zama |
|---|---|---|---|
| CPU 后端 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| GPU 后端 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| FPGA 后端 | ⭐⭐(预留) | ⭐⭐⭐ | ⭐⭐⭐⭐⭐(HPU) |
| 编译器 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| AI 推理优化 | ⭐⭐⭐⭐⭐(GIP) | ⭐⭐⭐ | ⭐⭐⭐ |
结语:FHE 全栈整合的工程路径
CipherFlow 的 LattiSense + LattiAI 展示了一条清晰的工程路径:从计算图定义到硬件执行的全栈垂直整合。与 LatticaAI 的 HEAL 硬件抽象层标准化路径不同,CipherFlow 选择自研编译器、调度器和算子库,最终用 GIP 方案解决了高分辨率图像 FHE 计算的行业瓶颈。
对于 FHE 研究者而言,CipherFlow 的开源策略(Apache 2.0)意味着可以:
- 研究 GIP 算法:深入分析高分辨率图像的打包技术
- 扩展硬件后端:在清晰的硬件抽象层上添加 FPGA/ASIC 支持
- 优化 AI 推理:基于完整的端到端 Pipeline 进行性能优化
随着 HEAL 确立硬件接入的行业标准,LattiSense 展示全栈整合的工程实践,隐私 AI 正在进入”百花齐放”的技术发展阶段。对于 FHE 研究者和 AI 工程师而言,未来的工作重心将是:如何在这两套稳固的技术架构之上,构建真正具备”模型隐私、逻辑验证、高吞吐”特性的下一代可信 AI 计算负载。