深刻影响AI工程和智能体发展的论文
业界每年产出数以万计的 AI 论文,本清单并非单纯的“高引用学术榜单”,而是基于 “真实工程落地价值” 与 “系统架构范式转移” 的双重视角筛选。
读者会在这篇文章中看到一种矛盾但真实的“工程冷水”:有些在大众眼中惊为天人的“神作”(如斯坦福 AI 小镇、多智能体自由对话),在追求 99.9% SLA、关注 Token 成本与延迟的一线工程师眼中,往往是极度不可控的“沙盒玩具”。真正的工业级 Agent 正在褪去早期的“拟人化”外衣,走向严谨的有向无环图(DAG)与状态机控制。理解这种从“学术浪漫”到“工程残酷”的落差,正是 AI 工程师进阶的必经之路。
前言
随着大语言模型(LLM)从 GPT-1 进化到如今的 Agent 智能体时代,人们容易陷入一个误区:认为 AI 应用效果的上限完全取决于基座模型的能力,工程师能做的只是“调用”和“等待”。然而,如果站在一线 AI工程(AI Engineering)和机器学习工程(ML Engineering)的视角,模型仅仅是系统中的一个非确定性计算引擎(或者说“大脑组件”)。
在真实的企业级落地中,工程师不只看“模型能做什么”,更看“代价是什么(Trade-off)”。从构建鲁棒的自动化评测集(Evals),到在“生成质量”与“响应延迟(Latency)”之间走钢丝;从抽象工具调用规范,到收集交互轨迹(Trajectories)构建数据飞轮(Data Flywheel)——工程师对场景的拆解能力、对状态机的控制力以及评测体系的搭建,才是决定产品最终体验的关键变量。在 AI 工程界有一句名言:“Evals are all you need”(评测即一切)。评测定义了系统的上限。
本文旨在以能力架构分层(Capability Stack)的视角,梳理那些深刻影响大模型与智能体发展的核心论文,展现 AI 工程师是如何一步步从“炼丹师”进化为驾驭复杂状态机的“系统架构师”与“数据流调配师”的。
Level 0: 基座与对齐 (Foundation & Alignment)
解决“模型听不懂人话、缺乏通识”的问题。
1. GPT-1: 范式的确立 (2018)
官网:Improving language understanding with unsupervised learning
论文:Improving Language Understanding by Generative Pre-Training (2018)
代码:openai/finetune-transformer-lm
在 GPT-1 出现之前,自然语言处理(NLP)领域通常面临着“一种任务一个模型”的困境:做翻译需要一种模型结构,做文本分类又需要另一种。GPT-1 提出了一个革命性的思想:能不能先用海量无标注文本训练一个“通用的语言理解模型”,然后针对特定任务只需微调(Fine-tune)一下?这就确立了“先预训练,再微调 (Pre-training + Fine-tuning)”的范式。
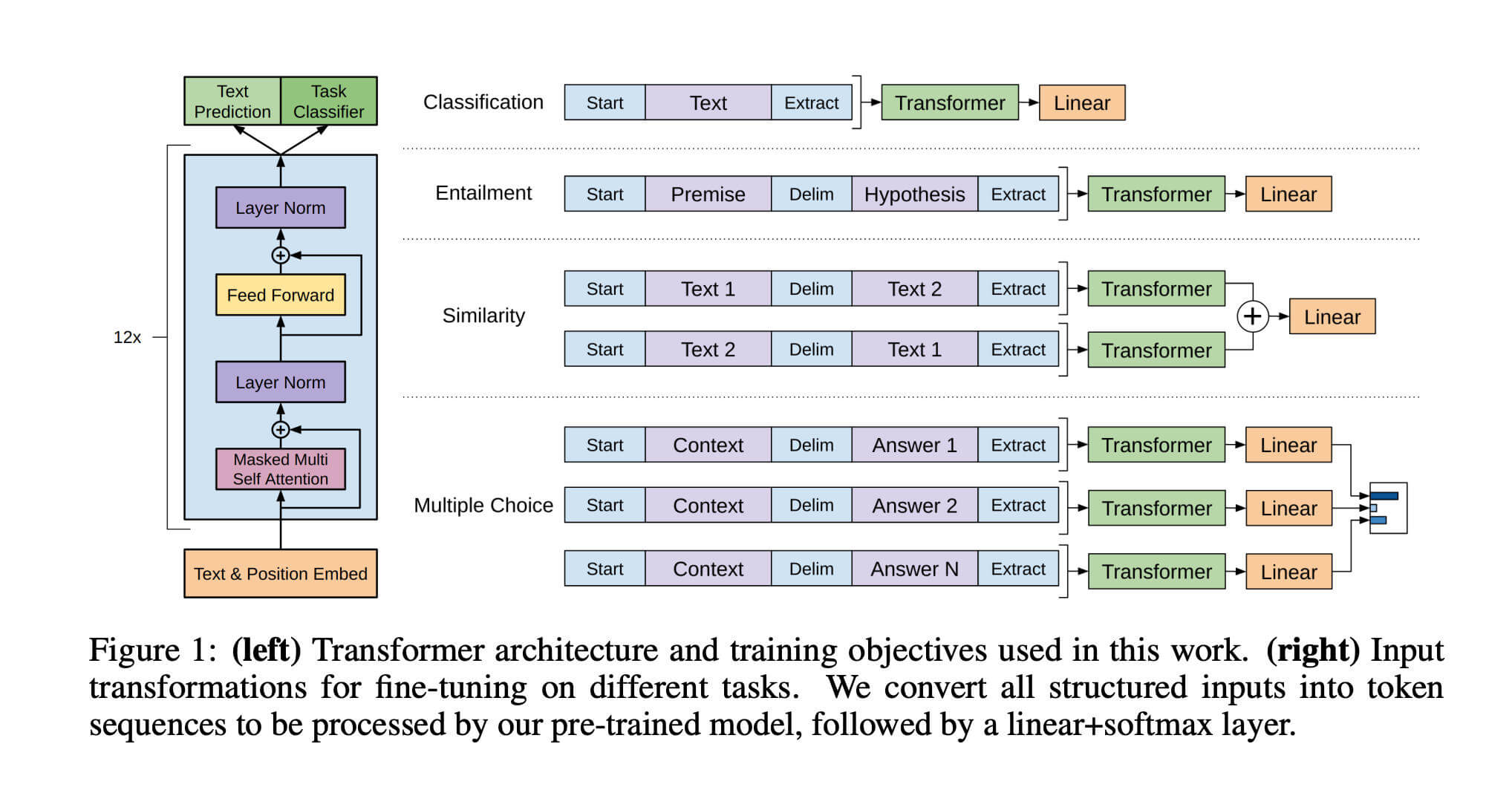
它的基本架构是 12 层的 Transformer Decoder(约 1.17 亿参数)。在第一阶段的无监督预训练中,模型在庞大的书籍数据上学习预测下一个词,从而掌握了语法、句法和世界知识;在第二阶段的有监督微调中,模型在特定任务的标注数据上调整参数以适应具体场景。
这一突破彻底结束了为每个任务单独设计模型结构的时代,确立了统治 NLP 领域多年的工业标准范式,同时也证明了 Transformer 结构在处理长文本依赖上显著优于此前的 RNN/LSTM。
尽管Pytorch已经是占据统治地位的深度学习框架,但GPT-1的代码还是使用TensorFlow训练,并且代码库已经在GitHub开源。
2. GPT-2: 走向通用与零样本 (2019)
官网:Better language models and their implications
论文:Language Models are Unsupervised Multitask Learners (2019)
代码:openai/gpt-2
GPT-2 的核心思想是探索“零样本学习 (Zero-shot Learning)”。OpenAI 团队发现,当模型足够大、喂给它的数据足够多时,模型似乎不再需要针对特定任务进行“微调”。他们提出了一个极具野心的理念:“所有的 NLP 任务本质上都是预测下一个词”。
在架构上,GPT-2 保持了与前代相似的结构,但参数规模扩大了 10 倍(达到 15 亿),并使用了高质量且多样性大增的 WebText 数据集。在使用机制上,它直接去掉了微调步骤,而是通过给模型输入提示(Prompt)来看看它能否直接输出答案。例如,给它输入 "English: Hello, French: ",它就能预测出 "Bonjour"。
GPT-2 证明了“大力出奇迹”的可行性:单纯增加模型参数和数据量,就能显著提升性能。它向世人展示了模型在没有见过某个任务专属数据的情况下,也能凭借海量的通用知识解决问题的巨大潜力。由于其生成文本的能力过于逼真,甚至一度引发了关于 AI 安全和假新闻的广泛讨论。
GPT-2仍然在GitHub上开源,与GPT-1一样使用TensorFlow而不是Pytorch训练和推理。
3. GPT-3: 暴力美学与涌现 (2020)
论文: Language Models are Few-Shot Learners (2020)
模型卡:openai/gpt-3
GPT-3 带来了对模型微调理念的彻底颠覆,其核心是“上下文学习 (In-context Learning / Few-Shot)”。它完全放弃了更新模型参数的想法,转而通过“提示工程”让模型在上下文中学习任务。只要在 Prompt 里给它几个例子(Few-shot),它就能瞬间学会规律并应用。

它的规模扩大到了惊人的 1750 亿参数,训练数据几乎吞噬了整个互联网(Common Crawl)。在推理时,模型不进行任何梯度下降,而是完全依赖其强大的模式匹配能力来理解用户的输入并生成后续内容。
GPT-3 最令人震撼的是“能力的涌现 (Emergence)”:当参数量突破千亿大关,模型突然具备了以前小模型完全没有的复杂逻辑推理和代码生成能力。它不仅催生了 Prompt Engineering 这一全新的交互方式,还通过提供商业化 API,证明了通用大模型可以作为基础设施支撑起无数下游应用,正式开启了生成式 AI 的商业浪潮。
OpenAI从GPT-3开始采取了闭源,并正式开启商业化。
4. GPT-3.5 (InstructGPT): 通过 RLHF 与人类意图对齐 (2022)
官网:Aligning language models to follow instructions
论文: Training language models to follow instructions with human feedback (2022)
尽管 GPT-3 非常强大,但它本质上仍是一个“文本补全机”。它可能用另一个问题来补全你的问题,或者生成不相关的废话,因为它并不真正理解用户的“意图”。GPT-3.5 (InstructGPT) 的核心思想就是“对齐 (Alignment)”,即将模型的优化目标从简单的“预测下一个词的概率最大化”调整为“符合人类意图和价值观”。
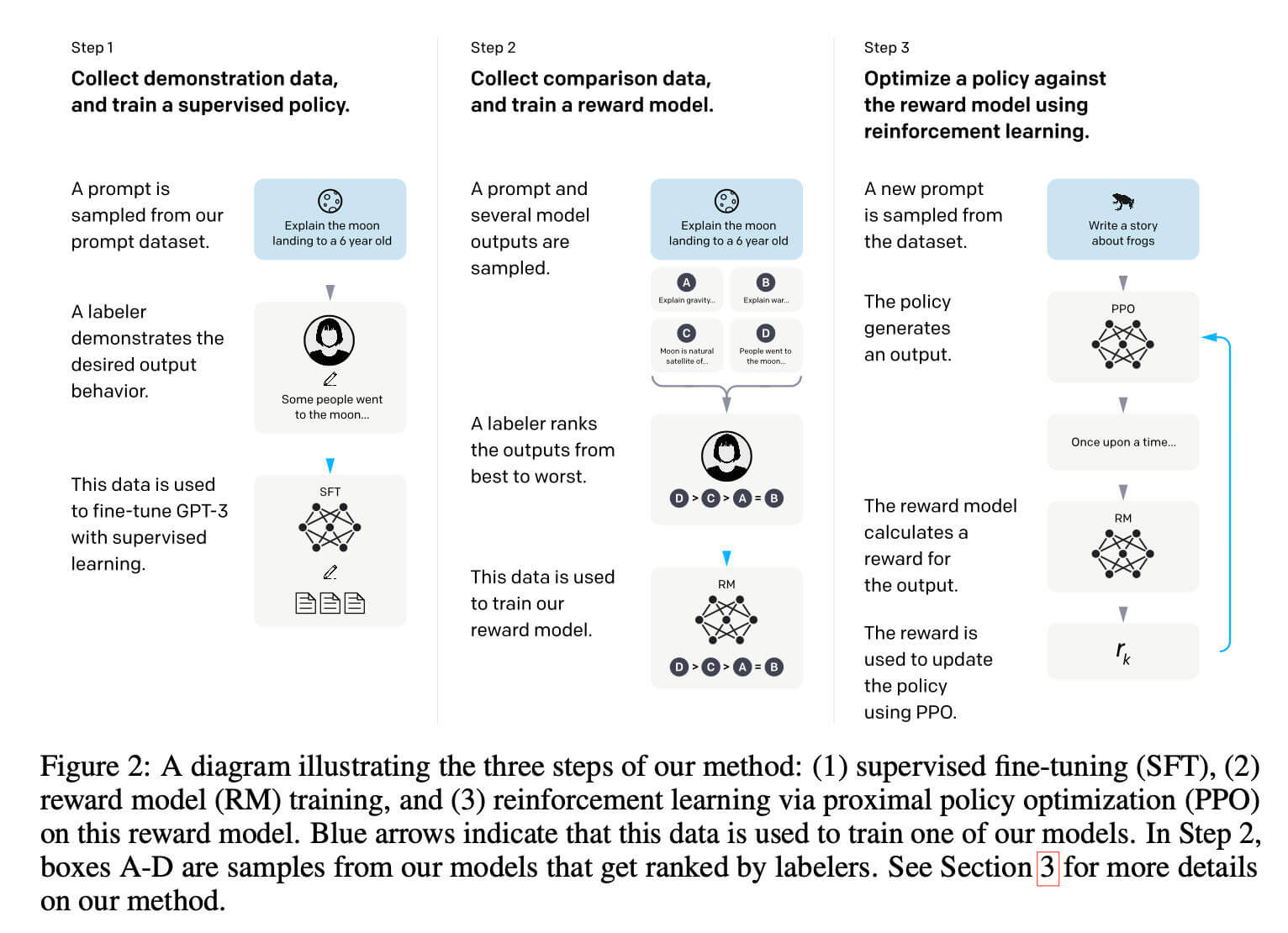
为了实现这一目标,GPT-3.5 采用了著名的 RLHF(基于人类反馈的强化学习)三阶段训练法。第一阶段是有监督微调(SFT),通过人类专家编写的高质量答案让模型学会基本的对话格式和逻辑;第二阶段是训练奖励模型(RM),让人类对模型的多个回答进行排序,从而训练出一个能够判断“什么回答更好”的打分模型。
第三阶段则是近端策略优化(PPO)。这是一个强化学习过程,主模型生成回答,奖励模型给出分数,分数高则鼓励,分数低则惩罚。通过机器大规模训练机器,模型实现了大规模的自我进化,使其回答越来越符合人类偏好,最终演变成了我们熟悉的 ChatGPT 的底层基座。
Level 1: 提示工程与推理期计算 (Inference-Time Compute)
解决“模型单次输出不可靠、缺乏深度思考”的问题。强调 Scaling Law 从 Training 转向 Inference 的工程趋势。
1. 思维链 (Chain-of-Thought, CoT) (2022)
论文: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022)
在处理复杂的数学或逻辑问题时,传统的提示方法通常是给模型一个问题,并期望它直接给出最终答案。而思维链(CoT)提出了一种极其简单而高效的提示方法:在给模型的少量示例中,不仅展示“问题”和“答案”,还要展示从问题推导到答案的“中间思考步骤”。
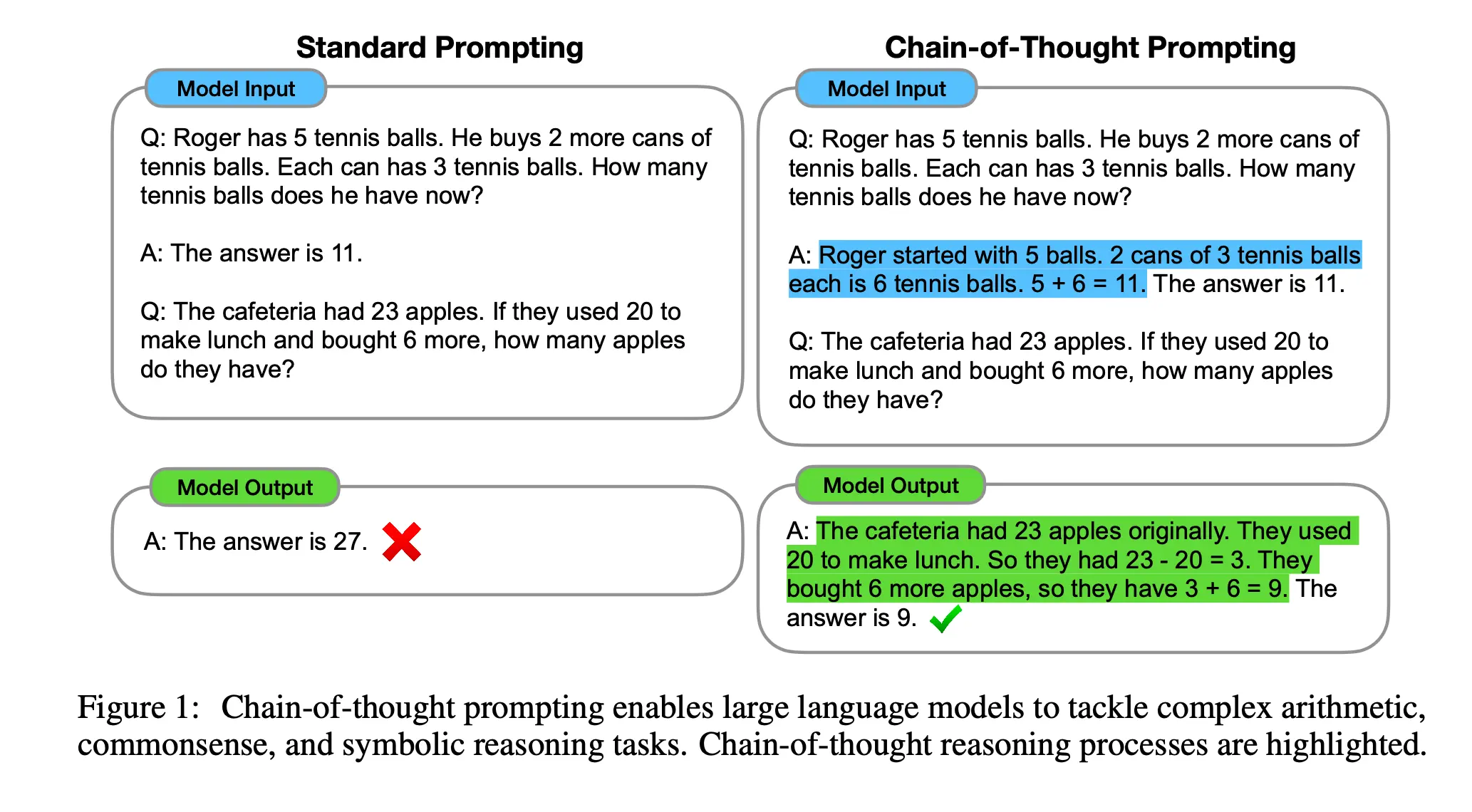
这种方法显著提升了大型语言模型在算术推理、常识推理和符号推理等复杂任务上的表现。尤其重要的是,论文发现这种推理能力是一种“涌现”特性,只有在参数量超过千亿的大模型上,CoT 才能发挥出神奇的效果,而在小模型上甚至可能起反作用。
CoT 不仅大幅提升了模型的准确率,还提供了解释性和可调试性。通过让模型输出推理步骤,研究人员可以“看到”模型的思考过程,从而在模型出错时定位具体的错误环节。这种无需额外训练、仅凭几个示例就能解锁大模型潜力的技巧,深刻改变了业界对模型能力的认知。
2. Zero-Shot CoT: 时代的眼泪与奇技淫巧 (2022)
论文: Large Language Models are Zero-Shot Reasoners (2022)
这篇论文在当时引起了巨大轰动,因为它发现了一个极其简单却强大的“咒语”:只需在提示词中加上一句 Let's think step by step(让我们一步步思考),就能直接唤醒模型的零样本逻辑推理能力。这强制模型进入了“分析式”模式(系统2思维),将 GPT-3 在 GSM8K 数学数据集上的准确率从 17.7% 飙升到了 78.7%。

但从现代 AIE 的残酷视角来看,这属于“时代的眼泪”——一种因为当时模型底层能力太弱而显得神乎其神的奇技淫巧。 在今天,诸如 GPT-4o、Claude 3.5 或是原生的强化学习推理模型(如 DeepSeek R1、OpenAI o1),其底层的对齐(Alignment)早已内化了这种分布。在系统工程中,我们现在更倾向于使用结构化的 XML 或 JSON(例如强制输出 <thinking> 标签)来强校验模型的思考状态,而不是依赖一句脆弱的自然语言咒语。它的历史意义在于向业界证明了:推理潜能早已藏在模型内部,只需被正确触发。
3. 自洽性 (Self-Consistency) (2022)
论文: Self-Consistency Improves Chain of Thought Reasoning in Language Models (2022)
自洽性(Self-Consistency)解决的是大模型在推理时偶尔“脑抽”犯错的问题。它的直觉非常朴素:复杂的推理问题通常有多种正确的解题思路,但它们最终都会指向同一个正确的答案;相反,如果模型推理错了,它出错的路径往往是发散且随机的。
因此,与其让模型只回答一次(贪婪解码),不如让它生成多条不同的推理路径(比如回答 10 次),直接统计最终结果,选取出现次数最多的那个答案作为最终输出(多数投票)。在多个算术和常识推理基准测试中,自洽性显著提高了思维链提示的性能。
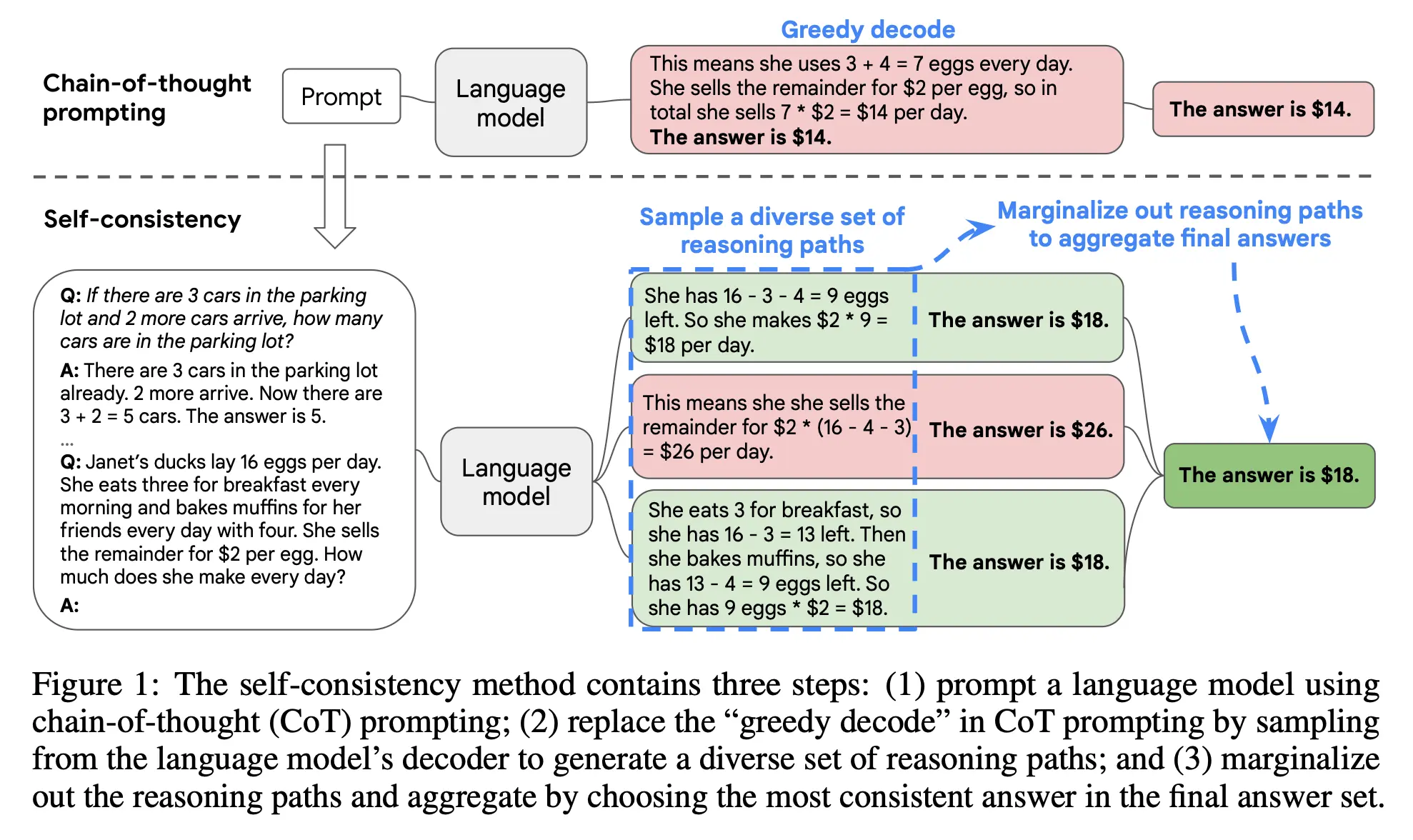
这篇论文确立了“推理时计算换智能 (Inference-time Compute)”的重要范式。它证明了即使不重新训练模型,仅仅通过增加推理阶段的计算量就能大幅提升模型的可靠性。但在工程实践中,这种能力提升的代价是极高的 Token 消耗和线性的延迟(Latency)增加。如何在生成质量与响应时间之间做好 Trade-off,成为了 AIE 部署此类方案时的核心痛点。
4. 思维树 (Tree of Thoughts, ToT): 成本刺客与离线蒸馏 (2023)
论文: Tree of Thoughts: Deliberate Problem Solving with Large Language Models (2023)
思维链(CoT)虽然有效,但它是一种“贪婪”的方法,一步一步线性生成,如果中间某一步走错了,模型就无法回头。思维树(ToT)则将人类的“系统2”思维引入到了大模型的生成过程中,将问题解决建模为在一棵“思维树”上的搜索过程。在当前节点让模型生成多个可能的“下一步”(分叉),然后充当“评估者”进行打分评估,决定是继续探索、剪枝还是回溯。
但在 MLE 眼中,ToT 是一个名副其实的“成本刺客”和生产环境的噩梦。 虽然它带来了极其惊艳的推理上限,但其节点呈指数级爆炸的搜索机制会导致灾难性的 Token 消耗,一次请求可能耗时数分钟并轻易触发 API 的限流(Rate Limit)。因此,在真实的工业级高并发在线(Online)服务中,ToT 几乎不被采用;工程师宁可把任务强行拆解为确定性的单步流,或使用高并发的 Best-of-N 采样。目前,ToT 的核心价值被“降维”到了算力富裕的离线(Offline)场景,作为合成高质量轨迹数据、蒸馏微调小模型(SLM)的利器。
5. 过程监督 (Process Supervision, PRM) (2023)
官网:Improving mathematical reasoning with process supervision
论文: Let’s Verify Step by Step (2023)
在训练 AI 解决复杂数学题时,传统的做法是“结果监督”:只有当模型输出完整个过程后,才检查最终答案是否正确。但这容易导致“歪打正着”,即模型推理全错但碰巧蒙对了答案。这篇论文提出,针对模型生成的每一个推理步骤进行评估的“过程监督(PRM)”,效果远优于结果监督。

为了证明这一点,OpenAI 甚至发布了包含 80 万个人工标注步骤的数据集 PRM800K,并通过主动学习让模型专门生成容易混淆的错题交由人类纠正。在推理阶段,模型生成多个方案,然后利用训练好的过程奖励模型(PRM)给每一步打分,选出总分最高的路径。这种方法让模型在复杂数学数据集上的准确率达到了惊人的 78%。
这项研究提出了“负对齐税”的概念:通常认为让 AI 更安全可解释会牺牲能力,但过程监督证明了,让模型一步一步正确思考不仅提升了解释性,还大幅提升了解题能力。这一理论奠定了后来 OpenAI o1 模型强大的长链条推理基础,并引领了训练专用验证器(Verifier)的行业新范式。
Level 2: 工具调用与环境感知 (Tools & Perception)
解决“模型没有手和眼、存在信息壁垒与幻觉”的问题。
1. Toolformer: 优美的构想与被取代的路径 (2023)
论文: Toolformer: Language Models Can Teach Themselves to Use Tools (2023)
大模型在数学计算或获取最新事实方面一直存在短板。Toolformer 探讨了如何让语言模型自主决定何时以及如何调用外部工具。与依赖大量人工标注的传统方法不同,Toolformer 提出了一种自监督学习的创新思路:在训练阶段,模型尝试插入 API 调用,如果结果有助于更准确地预测下一个词,就保留作为正向样本。最终模型学会了自然插入诸如 <API_Call> 的指令标记。
然而,这篇学术构想极美的论文,在工程界很快被“In-Context Learning + 强力 JSON 解析”的暴力美学所取代。 Toolformer 依赖于微调(Fine-tuning)来让特定模型学会调用语法。这在生产环境中极不灵活:如果业务 API 的参数今天改了,难道我们要重新微调模型吗?尽管如此,Toolformer 首次确立了“模型自主决定何时调用外部工具”的范式,直接启发了整个插件生态。
2. Gorilla 与 Function Calling: 结构化输出的工程规范 (2023)
论文: Gorilla: Large Language Model Connected with Massive APIs (2023)
在学术界证明了模型可以调用工具后,工程界遇到了一堵高墙:如何让不可靠的生成式模型稳定输出符合语法的 JSON 参数?如果解析失败,整个智能体状态机就会崩溃。Gorilla 论文通过检索增强训练(Retriever-Aware Training),证明了通过微调可以让大模型极大地减少 API 调用的幻觉并动态适应文档变化。
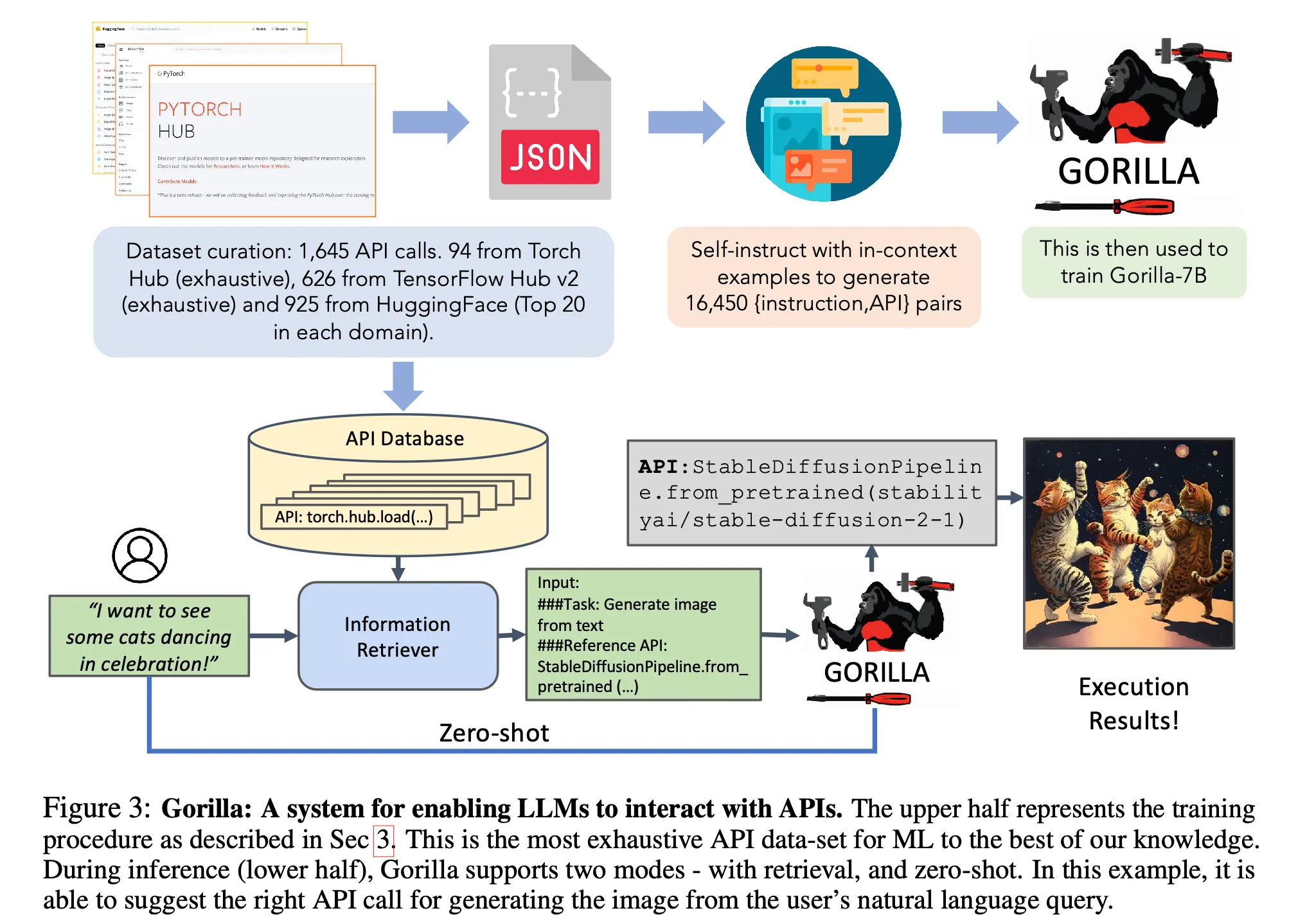
随后 OpenAI 正式推出了 Function Calling(函数调用 / JSON Mode)功能。在 AIE 眼中,这一特性是 Agent 真正走向大规模工业落地的核心转折点。它抛弃了不靠谱的正则提取,将提示词解析的“脏活累活”转移到了模型底层逻辑中,使得模型可以稳定地与外部数据库、业务 API 进行确定性交互,奠定了现代 Agent 工具链不可逾越的基础。
3. FLARE: 解决长文本幻觉的主动检索 (2023)
论文: Active Retrieval Augmented Generation (2023)
检索增强生成(RAG)是解决大模型幻觉和企业私有数据接入的最有效工程手段。传统的 RAG 通常只在生成前进行一次“静态检索”。但在生成长篇技术文档时,模型中途往往会“忘记”上下文信息并开始胡编乱造。
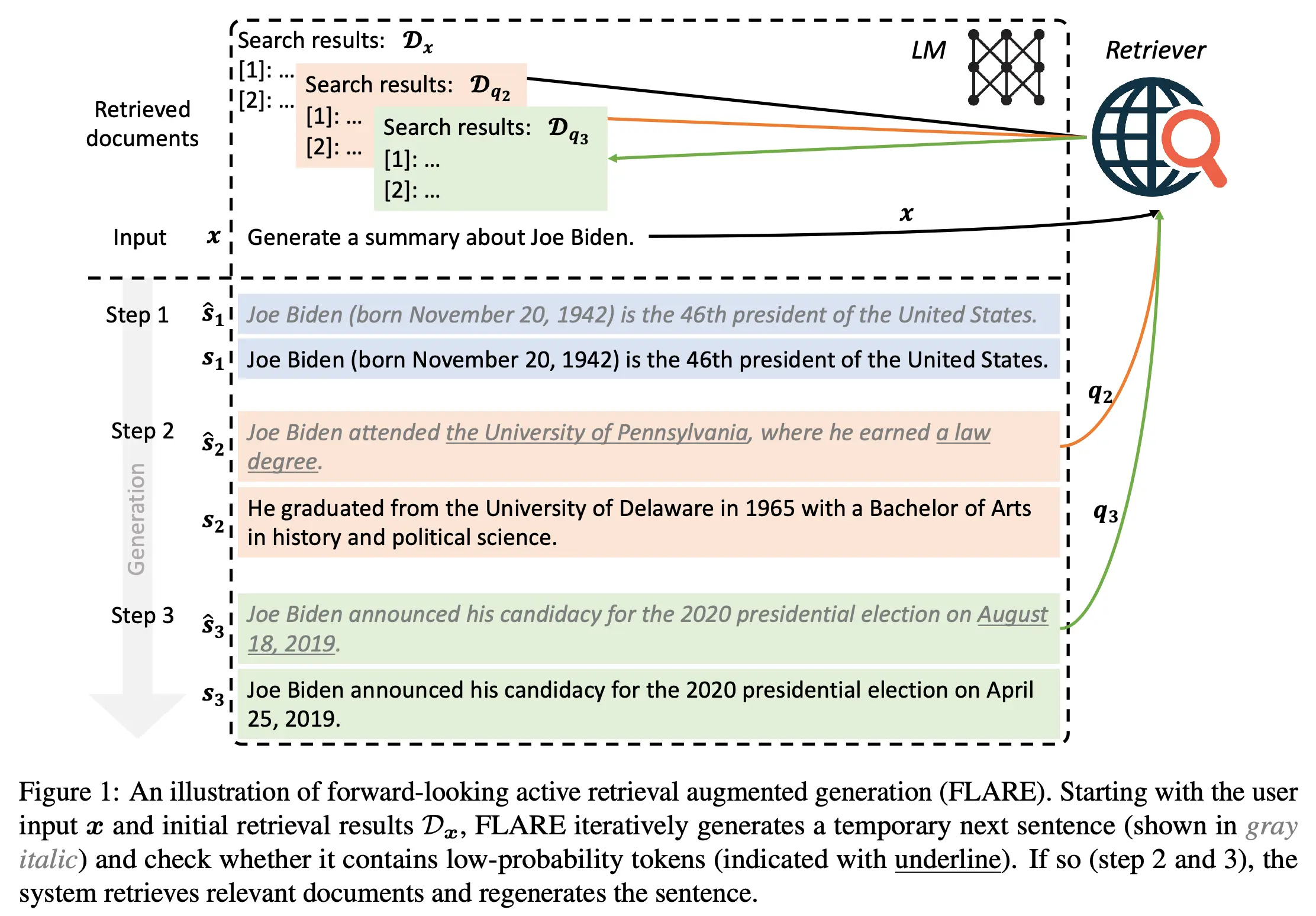
FLARE 提出了一种“前瞻性主动检索”机制:模型在生成过程中会实时监控自身的置信度(Probability)。一旦发现接下来要生成的词汇置信度极低,它就会主动停下来,生成一个“预测性句子”作为 Query 去检索外部知识库,然后再基于检索结果继续生成。这种细粒度的状态机控制,极大地提升了长链路生成任务的可靠性和事实正确性。
4. AppAgent: 跨越 API 限制的 GUI 智能体 (2023)
论文: AppAgent: Multimodal Agents as Smartphone Users (2023)
长久以来,AI 智能体操作外部软件都严重依赖于系统后端的 API。这种方式的致命弱点在于:一旦软件没有开放 API,智能体就束手无策。AppAgent 提出了一种极具颠覆性的多模态智能体框架:让大模型直接像人类一样,通过“看”屏幕截图并进行点击、滑动等触屏手势来操作真实的智能手机。
AppAgent 引入了创新的“两阶段学习”机制。在探索阶段,智能体通过自主尝试或观察人类示范,建立起对某个 App 界面的认知;在部署阶段,它就能基于知识库识别屏幕元素,并直接操作应用以完成复杂任务。它拉开了“Computer Use(计算机使用)”智能体时代的序幕,为后来操作系统级别的 Agent 发展奠定了重要基础。
Level 3: 认知架构与记忆系统 (Cognitive Architecture & Memory)
解决“模型健忘和无法自我迭代”的问题。
1. ReAct: 思考与行动的“双螺旋”状态机 (2022)
论文: ReAct: Synergizing Reasoning and Acting in Language Models (2022)
在 ReAct 之前,大模型主要被用于纯推理(容易因缺乏外部信息而产生幻觉)或纯行动(直接调用工具但缺乏规划,容易死循环)。ReAct 框架巧妙地将“推理 (Reasoning)”和“行动 (Acting)”交织在一起,让模型能够“一边思考,一边干活”。

ReAct 的工作流遵循一个特定的循环模式:Thought -> Action -> Observation。从工程视角来看,ReAct 实际上是将大模型封装成了一个受控的非确定性状态机 (State Machine)。 通过引入观察(Observation)节点,开发者能够捕获外部环境的异常报错(Error Handling),并强制模型在下一个循环中修复这些错误。这种坚实的工程抽象定义了现代 LangChain 等框架的底层运行逻辑。
ReAct几乎是所有智能体控制框架的基础。它的创新性在于定义了智能体事件循环的基本步骤,这一模式陆续被LangChain(create_react_agent())、CrewAI、AutoGen等。
2. Reflexion: 闭环反思与记忆反馈 (2023)
论文: Reflexion: Language Agents with Verbal Reinforcement Learning (2023)
传统的智能体在执行任务失败后,往往无法吸取教训,下次还会犯同样的错误。Reflexion 框架赋予了 AI 像人类一样“事后反思”的能力,开创了一种不需要微调模型权重就能实现自我迭代和进化的新方法,作者将其称为“语言强化学习 (Verbal Reinforcement Learning)”。

当智能体在任务中失败时,系统会启动一个“反思者”模块。它会分析失败的行动轨迹和环境反馈(例如代码编译报错),然后用自然语言生成一段反思笔记存入长期记忆库,并在下一次尝试时作为额外的上下文提示喂给模型。Reflexion 让智能体不再是一次性的消耗品,而成为了一个可以通过试错不断进化的“问题解决者”。
3. 生成式智能体 (Generative Agents): 认知架构的沙盒玩具 (2023)
论文: Generative Agents: Interactive Simulacra of Human Behavior (2023)
这篇论文通常被称为“斯坦福 AI 小镇”,研究者在一个 2D 沙箱世界中投放了 25 个由大模型驱动的虚拟人物。最大突破在于为 Agent 设计了一个包含“记忆流 (Memory Stream)”的认知架构:系统记录所有经历,定期停下来轮询“反思”提炼高级认知,接着“规划”,并在行动时“检索”庞大的记忆库。
但如果摘下“西部世界雏形”的浪漫滤镜,高级 AIE 对这种架构抱有天生的警惕:在严肃的 B2B/B2C 商业系统中,这种极度拟人化的设计是冗余且不可控的“沙盒玩具”。 工业界绝不允许代码 Agent 或自动化客服拥有这种“自由散漫的反思机制”去消耗惊人的 Token。真实的生产记忆系统往往抛弃了昂贵的 LLM 轮询反思,转而采用精准的向量数据库(Vector DB)结合传统关系型数据库(SQL)进行强规则过滤。尽管它在严肃工程中落地受限,但它为游戏 NPC、社会科学模拟提供了极其珍贵的认知实验样本。
Level 4: 多智能体协同与工作流编排 (Orchestration & Workflow)
解决“复杂长链路任务的鲁棒性”问题,从纯 Agentic 走向规矩的工作流编排。
1. CAMEL: 多智能体对口相声的终结 (2023)
论文: CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society (2023)
CAMEL 提出了“角色扮演框架”,给两个智能体设定严格的角色(用户智能体发指令,助手智能体执行),试图规范智能体之间的有效沟通,解决控制权混乱的问题。
在学术界,CAMEL 启发了多智能体的发展;但在工程界,让两个 LLM 通过自然语言“自由对话(哪怕限定了角色)”来推进任务,很快被证明是一场灾难。 概率生成模型在自由对话中极其容易陷入死循环、互相吹捧或偏离主题。现代工业界构建 Multi-Agent 早已抛弃了这种不可控的“聊天流”,转而走向有向无环图(DAG,如 LangGraph)或严格的状态机(State Machine)。前一个 Agent 生成的内容必须是严谨的 JSON,经过代码逻辑强校验后才传给下游。CAMEL 的宿命是证明了“多 Agent 协同”的价值,但也反向证明了“不可控对话”在复杂交付中的极大局限性。
2. MetaGPT: 引入人类 SOP 的多智能体流水线 (2023)
论文: MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework (2023)
针对自由对话容易跑偏的痛点,MetaGPT 创造性地将人类企业管理中的标准化作业程序(SOPs)引入到了多智能体协作中。
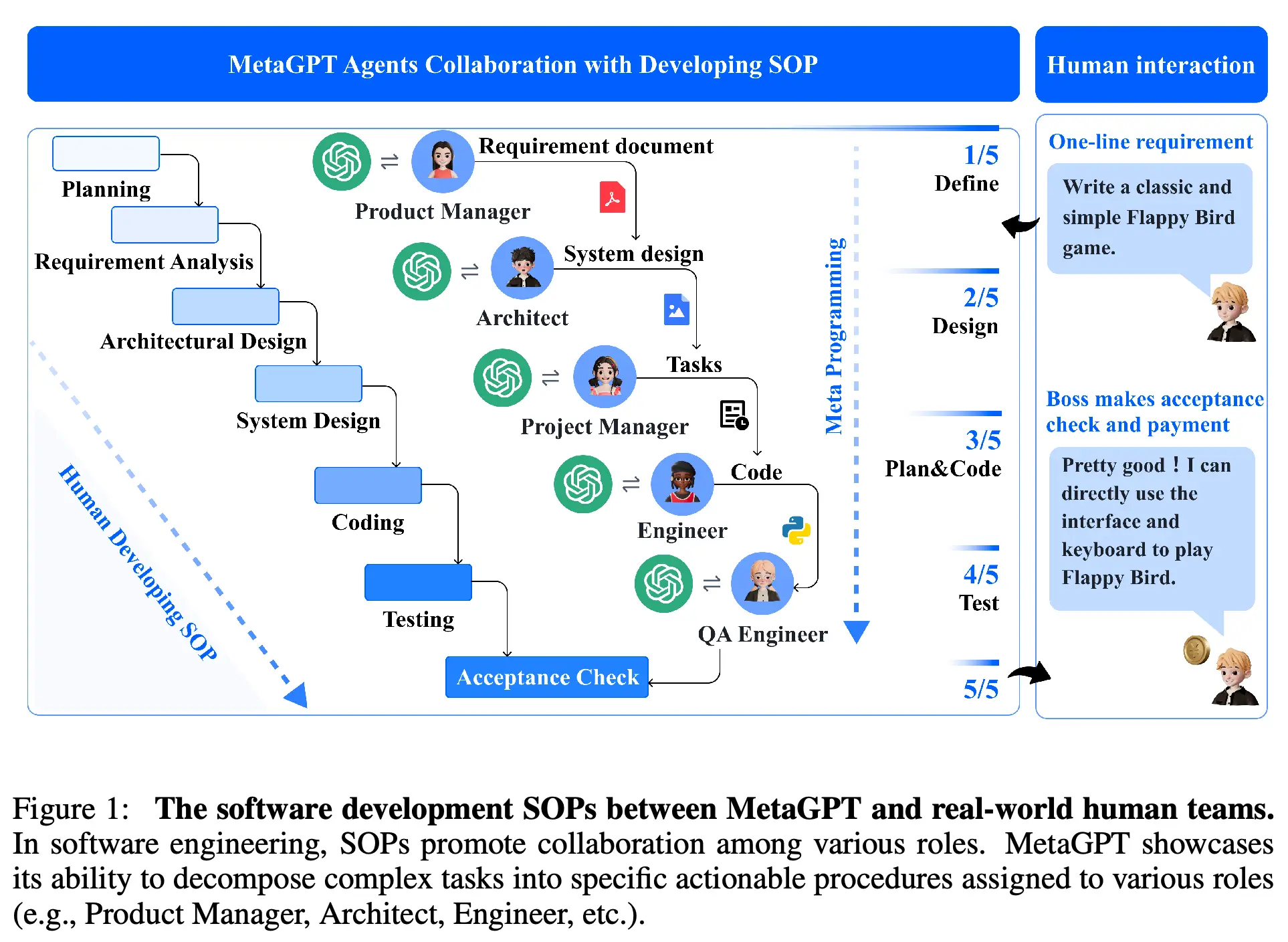
在 MetaGPT 的框架内,预设了产品经理、架构师、工程师、QA 等核心角色。智能体之间不再通过随意的聊天交接工作,而是严格按照流水的形式,上游角色输出结构化文档(如 PRD 需求文档、UML 架构图),下游角色基于这些文档进行开发和测试。这种将软件工程经验“Prompt 化”的做法,通过强制的中间文档产出,引入了极强的“自我修正”和“逻辑验证”机制。
3. AutoGen: 多智能体编排与对话编程 (2023)
论文: AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation (2023)
微软推出的 AutoGen 提供了一个框架,让开发者可以定义各种具有不同能力、不同工具权限的 Agent,并设定它们之间的交互拓扑结构,从而开发复杂的大模型应用。
对于 AI 工程师而言,AutoGen 最大的价值在于它提供了一套优雅的并发控制、上下文状态共享 (Context Management) 以及截断策略 (Truncation)。 复杂任务被拆解给不同的 Agent 状态机,极大地缓解了单个模型上下文窗口满溢的压力,使得复杂任务的工程编排成为现实。
4. Mixture-of-Agents (MoA): 模型的群智涌现 (2024)
论文: Mixture-of-Agents Enhances Large Language Model Capabilities (2024)
当单体大模型的发展逼近算力的瓶颈时,MoA 架构发现了一个“协作现象”:当模型被提供其他模型的输出作为参考时,它往往能生成比单独思考时更高质量的回答。在“提议者”层,多个不同 LLM 并行生成初始回答;在“聚合者”层,模型进行综合与提炼,这让纯开源模型组合在评测上超越了闭源巨头 GPT-4o。
然而,AIE 必须面对现实:MoA 在离线打榜时无敌,但在高并发的在线服务中,其多层级、多模型的网络请求开销是一场工程噩梦。它更多被作为生成高质量蒸馏数据的基础设施,而非直接面向 C 端的接口。
Level 5: 垂直领域实战与全栈自动化 (Verticals & Full-Stack Automation)
走向开放环境与代码库中的自主实战。
1. SWE-bench: 真实软件工程的终极评测 (2023)
论文/数据集: SWE-bench: Can Language Models Resolve Real-World GitHub Issues? (2023)
SWE-bench 改变了 AI 编程能力的测试规则。它要求 AI 在包含几十万行代码的真实开源库(如 Django、pandas)中,根据一段 Issue 描述,定位并修复 Bug。
这种“噩梦级”的任务要求模型具备处理超长上下文、理解复杂环境依赖和进行多步推理的能力。SWE-bench 的出现直接催生了 AI 软件工程 Agent(如 SWE-agent、OpenHands、Devin)的爆发。它向行业昭示:在复杂的垂直领域,Evals (自动化评测集) 的质量决定了 Agent 能力迭代的上限。 开发者必须让系统学会像人类程序员一样:加日志、运行代码、看报错、再修改。
2. Voyager: 具身智能与技能库沉积 (2023)
论文: Voyager: An Open-Ended Embodied Agent with Large Language Models (2023)
Voyager 将大语言模型作为核心控制器,在《我的世界》(Minecraft) 中构建了一个能够持续探索、学习新技能并自我驱动的具身智能体。
它的核心机制由三个关键模块组成:一个最大化探索的“自动课程”、一个存储可执行代码的“技能库”,以及一个基于环境反馈的迭代提示机制。当代码成功执行完成任务时,代码会被封装成“技能”永久保存。Voyager 首次展示了无需人类干预的“终身学习”能力。
3. The AI Scientist: 迈向全自动化的科研闭环 (2024)
论文: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery (2024)
The AI Scientist 标志着 AI 智能体正式进入了“全栈式科研”的深水区。它提出了世界上第一个全面自动化科学研究全过程的 AI 系统,能够自主完成从提出创新想法、进行实验,到撰写完整学术论文的闭环。
系统甚至内置了一个“自动化审稿人 (Automated Reviewer)”,能像顶级会议的评审一样对生成的论文打分并提出修改意见。它打破了“AI 只能作为辅助工具”的传统认知,展示了 AI 作为“独立研究员”的巨大潜力。
Level 6: 基础设施、自我进化与微型化 (Infrastructure, Self-Evolution & SLM)
解决碎片化、高昂推理成本以及端侧部署难题。
1. 智能体基础设施的标准化:MCP (2024)
项目/协议: Model Context Protocol (MCP) (2024)
MCP 提出了一种标准化的客户端-服务器架构,规范了智能体如何在不同的模型和工具之间共享、保留和检索上下文。
MCP 的核心突破在于它将“数据源”与“大模型”完全解耦。只要开发者为某个数据源编写了标准的 MCP Server,任何支持 MCP 的客户端都可以直接读取数据。这让跨应用的多步 Agent 工作流变得稳定可靠,为开放式智能体生态奠定了网络协议基础。
2. 强化学习与推理革命:DeepSeek R1 (2025)
论文: DeepSeek R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2025)
DeepSeek R1 首次证明了,纯粹通过大规模强化学习(RL),在极少甚至没有标注数据的情况下,模型也能自发涌现出高级的自我反思、错误修正和长思维链能力。
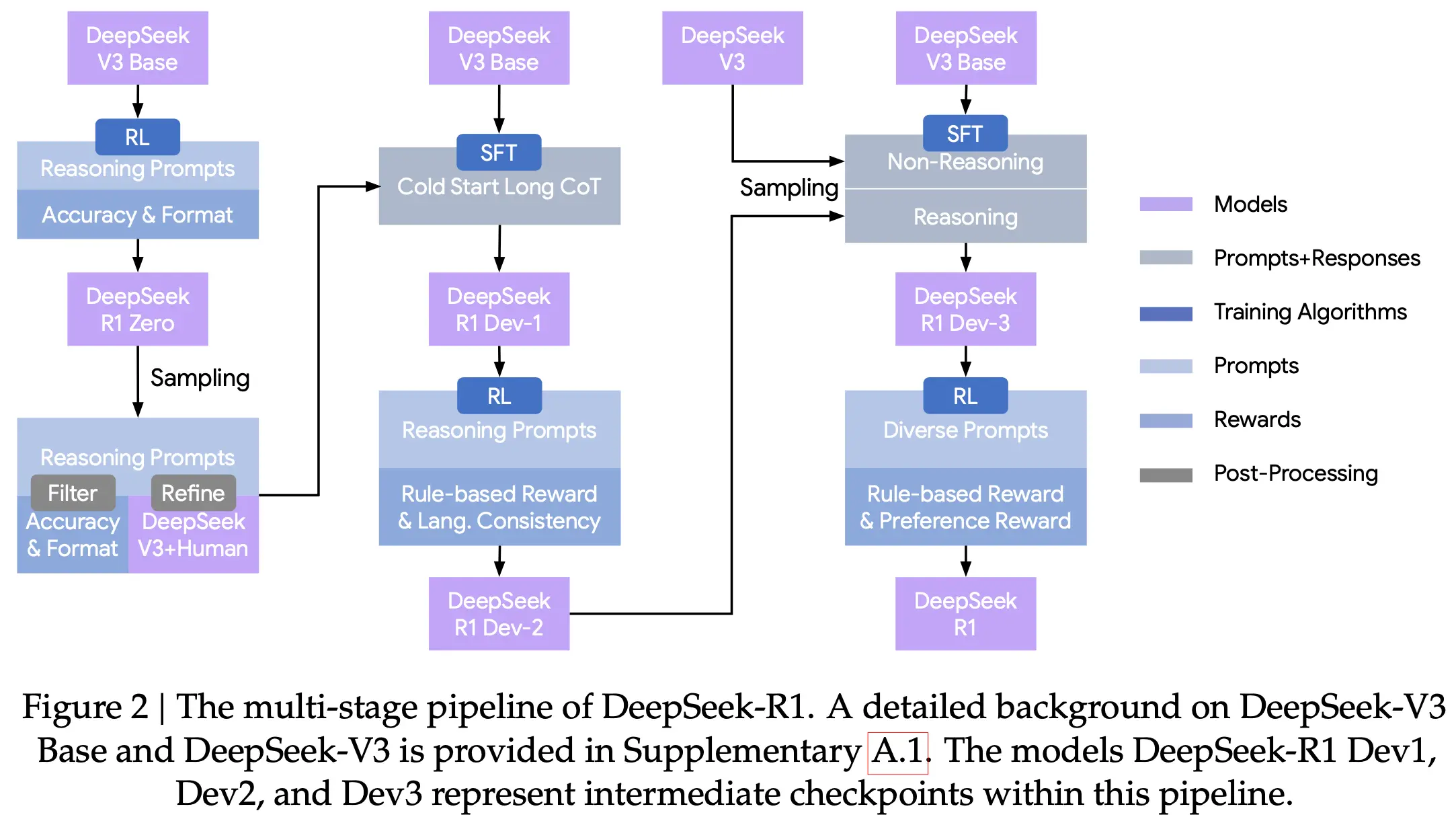
它的核心机制在于设计了一个极其巧妙的奖励函数,去掉了传统 RLHF 中需要人类偏好的奖励模型,直接根据数学题的对错或代码能否编译通过给出硬性奖励(Rule-based Reward)。这彻底颠覆了智能体的推理底座,将顶级逻辑推理能力的成本降低了几个数量级。
3. 微型化与协同:Agentic AI 的 SLM 趋势 (2025)
论文: Small Language Models (SLMs) are the Future of Agentic AI (2025)
随着智能体被广泛应用,人们发现用千亿参数的巨型模型去执行简单任务是极度浪费计算资源的。小语言模型(SLMs)被认为是未来 Agent 系统的基石。
研究者展示了“管理者-打工人(Manager-Worker)”架构:由极强的大模型担任 Manager,负责全局规划;具体的执行工作交由微调后的 SLM Workers 负责。这使得 AI Agent 能够以极低的延迟和成本部署在端侧设备上。
结语
当我们回顾从 GPT-1 到 Multi-Agent,再到如今的自动化工作流这段波澜壮阔的演进史,关于“AI 工程师的空间在哪儿”这个问题的答案,其实已经浮现在每一次范式的跃迁之中。
起初,我们以为工程师的空间在于“训练”——在参数的海洋里寻找收敛的彼岸;后来,我们以为空间在于“提示”——试图用咒语般的 Prompt 唤醒巨人的沉睡;但现在,真正的工程师空间,在于 “系统构建”与“数据飞轮”。
大模型本身正在变成计算机的新型 CPU。它拥有惊人的算力和通识,但它作为一个非确定性的组件,依然会有幻觉、会遗忘、会产生高昂的延迟。AI 工程师的使命,不再是去打磨这颗 CPU 的晶体管,而是围绕这颗 CPU,去构建严谨的状态机主板(流程编排与错误恢复)、高速缓存与硬盘(RAG 与记忆系统)、外设网卡(Function Calling 与 MCP),以及最为关键的——评测监控仪(Evals)。
更进一步,优秀的AI工程师和 ML工程师知道,每一次 Agent 的试错与回滚,都是无比珍贵的轨迹数据(Trajectories)。通过收集这些交互数据进行 SFT 或 RLHF 反哺,专有小模型(SLM)将变得越来越强大。在这个时代,我们不仅是硅基大脑的系统架构师,更是数据流向的调配师。模型决定了单次响应的下限,而卓越的工程架构与持续运转的数据飞轮,决定了 AI 产品的绝对上限。这,就是属于我们的广阔空间。