全同态加密数据上的 GBDT 之一:明文训练加密推理
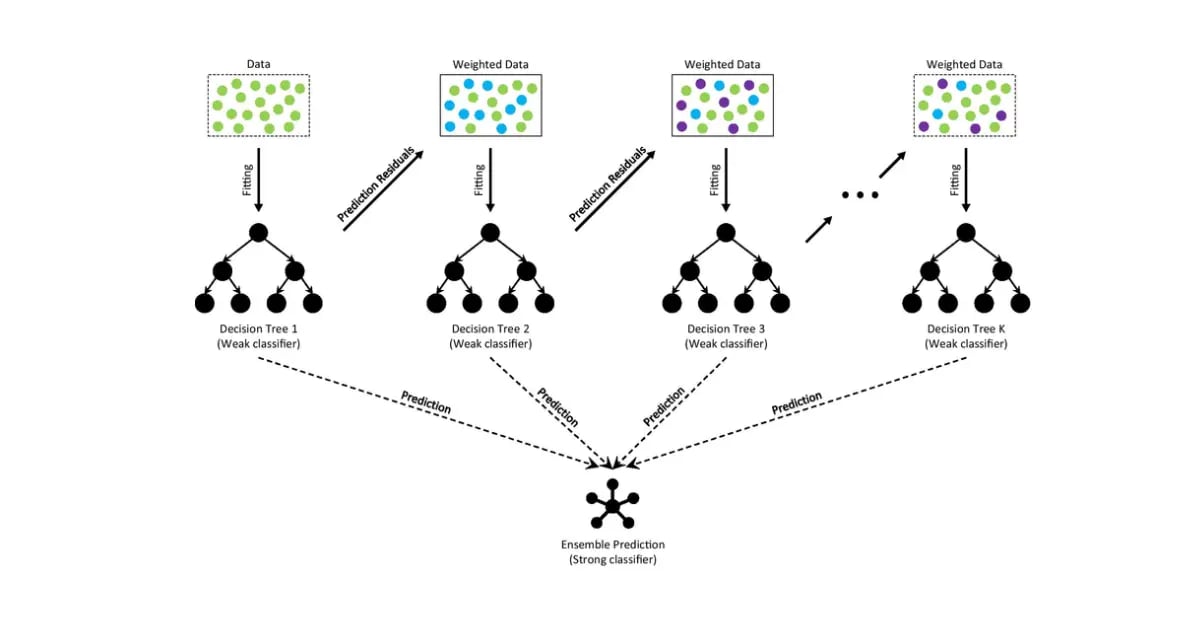
挑战:隐私保护的集成学习
梯度提升决策树(GBDT)是现代机器学习的核心算法,但在”机器学习即服务”(MLaaS)场景下,部署 GBDT 会陷入隐私困境:客户端不愿暴露敏感特征,服务提供商又必须保护自有模型。
同态加密(HE)提供了一条出路——它允许服务提供商直接在加密数据上进行计算。然而,学术论文与生产级实现之间始终存在一道鸿沟:论文往往只用寥寥数语带过最棘手的部分——分支逻辑如何映射为算术运算、乘法深度如何控制、ML 栈如何与 HE 运行时衔接。
本文将基于 Xiao 等人 (2019) 提出的基础方法,介绍如何使用 CKKS(Cheon-Kim-Kim-Song)方案在加密数据上构建 GBDT 推理引擎。
这是隐私保护机器学习系列文章的第一篇。你可以在 github.com/chuckchen/ckks-gbdt 找到参考实现。
结果摘要
在展开架构细节之前,先来看实现效果——在留出测试集上,与明文基准的对比:
| 数据集 | 指标 | 明文 (基准) | 加密 (再现) | 差距 |
|---|---|---|---|---|
| Credit | Micro-F1 | 0.7344 | 0.7188 | -0.0156 |
| MNIST | Micro-F1 | 1.0000 | 0.8750* | -0.1250 |
*注:MNIST 的加密结果来自 HE 风格的替代模型(多项式近似),用于验证路由逻辑是否正确,而非在多分类集成上跑完整的 CKKS 推理——后者的计算开销极大。
1. 核心思想:多项式化
HE 的核心问题在于它仅支持加法和乘法。在标准的 GBDT 中,内部节点 的分裂是一个离散的选择:
要在 CKKS 方案中完成这一计算,我们必须将控制流转化为连续的算术电路。
近似比较操作
我们首先用“软”路由变量 替换离散指示函数。理想情况下,,但由于符号函数是不连续的,我们使用参数化的 Sigmoid 函数来近似它:
其中 是陡度参数(通常取 128)。这为我们提供了一个近似值 ,如果满足条件,则 ,否则 。
决策树多项式
Xiao 等人论文的定理 1 证明了任何决策树 都可以唯一地表示为多项式 。对于具有左子节点 和右子节点 的节点 ,其输出以递归方式定义:
通过展开此递归,一棵树的最终得分是来自每个叶子节点 的贡献之和:
其中,如果路径在节点 处向左走,则条件项 为 ;如果向右走,则为 。这样,离散的决策树就转化为了 CKKS 可以计算的乘积求和电路。
为什么选择 Chebyshev 多项式?
要在同态环境下计算 Sigmoid 函数,我们使用 24 阶 Chebyshev 多项式。泰勒级数只是局部近似,而 Chebyshev 多项式能在整个区间(通常为 )上最小化最大误差( 范数)。这意味着即使输入值远离阈值,近似结果依然稳定,从而避免在更深的树层级出现错误路由。
2. 扩展性优化: 深度
如果按递归方式逐层求值,乘法深度会随树的深度线性增长。而在 FHE 中,乘法深度是最珍贵的资源。
Xiao 等人提出了一种 平衡乘积树(Balanced Product Tree) 策略,可将深度降至 。与其按顺序逐个相乘路径项:
我们将其成对并执行并行乘法:
这种策略将电路深度控制在合理范围内,使我们在不耗尽 CKKS 模数链的前提下也能支持更深的集成模型。
3. 系统优化:垂直打包 (Vertical Packing)
CKKS 的效率来自于 SIMD(单指令多数据)操作。大多数 ML 实现是按行组织的(一个样本包含所有特征),但构建高效的加密运行时,需要切换到 ”面向列” 的思路。
垂直打包 的做法是:将多个不同样本的 同一特征 打进同一个密文。
- 优势: 当节点按特征 分裂时,只需加载一个密文 ()。
- 规模: 单次同态运算可以同时处理数千个样本(如 8,192 个槽位)。
- 延迟与批量解耦: 批量推理的延迟几乎只取决于模型复杂度,而与批量大小无关(在槽位限制内)。
4. 实现架构
构建生产级的 HE 系统,要求在 ML 栈与加密电路之间划清边界。
第 1 层:预处理流水线 (Python)
我们使用 lightgbm 训练模型,然后将模型导出为扁平的、不依赖具体库的中间格式 (model.txt)。
- 学习率内化: 导出时,我们直接将学习率(shrinkage)乘进叶子节点的值里。这为每棵树节省了一次密文乘法和一次 rescale 操作——这是一个关键优化,往往决定了深层电路能否跑通。
第 2 层:同态运行时 (C++)
基于原始 HEAAN 库构建,运行时加载树的参数并执行 电路,同时使用 Paterson-Stockmeyer 算法 来减少非标量乘法。
5. 性能与误差界限
Xiao 等人提供了一个关键的绝对误差 理论界限:
由于 GBDT 是许多树的集成,偏导数 通常很小,有助于保持整体误差在界限内,即使特征数量 增加。
调试算术预算
最难排查的 Bug 往往不是典型的 C++ 错误(如段错误),而是 HE 算术层面的故障。例如,NTL 抛出的 division by zero in _ntl_gdiv 通常是模数耗尽的表现。在 FHE 中,”算密码学预算”取代了”数 FLOPs”——解决方法往往不是修改逻辑,而是调整 CKKS 参数或重排路径乘积树,省出一层乘法深度。
结语
构建这个系统最大的收获,是让论文中的抽象概念接受真实约束——文件格式、构建系统和模数预算——的检验。正是在理论与实践的碰撞中,才能获得最有价值的工程洞察。
在下一篇文章中,我们将探讨 MNIST 挑战:将这一架构扩展到多分类场景,并应对类别数量增加带来的乘法深度需求指数级增长。